Một trong những thách thức bao trùm của kỷ nguyên kỹ thuật số là quyền riêng tư của dữ liệu. Vì dữ liệu là mạch máu của trí tuệ nhân tạo hiện đại, các vấn đề về quyền riêng tư của dữ liệu đóng một vai trò quan trọng (và thường là giới hạn) trong quỹ đạo của AI. Trí tuệ nhân tạo bảo vệ quyền riêng tư – các phương pháp cho phép các mô hình AI học hỏi từ bộ dữ liệu mà không ảnh hưởng đến quyền riêng tư của chúng – do đó nó ngày càng trở thành mục tiêu theo đuổi quan trọng. Có lẽ cách tiếp cận hứa hẹn nhất để bảo vệ quyền riêng tư của AI là giải háp học liên kết hay Federated Learning.
Khái niệm về học liên kết lần đầu tiên được các nhà nghiên cứu tại Google đưa ra vào đầu năm 2017. Trong năm qua, mối quan tâm đến học liên kết đã bùng nổ: hơn 1.000 bài nghiên cứu về học liên kết đã được xuất bản trong sáu tháng đầu năm 2020, so với chỉ 180 bài. trong tất cả năm 2018.
Cách tiếp cận tiêu chuẩn để xây dựng mô hình học máy ngày nay là tập hợp tất cả dữ liệu đào tạo ở một nơi, thường là trên đám mây, và sau đó đào tạo mô hình trên dữ liệu. Nhưng cách tiếp cận này không khả thi đối với phần lớn dữ liệu trên thế giới, vì lý do riêng tư và bảo mật không thể chuyển đến kho lưu trữ dữ liệu trung tâm. Điều này làm cho nó vượt quá giới hạn đối với các kỹ thuật AI truyền thống.
Học tập liên kết giải quyết vấn đề này bằng cách lật lại phương pháp tiếp cận thông thường đối với AI.
Thay vì yêu cầu một tập dữ liệu thống nhất để đào tạo một mô hình, việc học liên kết sẽ để dữ liệu ở vị trí của nó, được phân phối trên nhiều thiết bị và máy chủ. Thay vào đó, nhiều phiên bản của mô hình được gửi đi — một đến mỗi thiết bị có dữ liệu huấn luyện — và được huấn luyện cục bộ trên mỗi tập con dữ liệu. Các tham số mô hình kết quả, nhưng không phải dữ liệu đào tạo, sau đó được gửi trở lại đám mây. Khi tất cả các “mô hình nhỏ” này được tổng hợp, kết quả là một mô hình tổng thể hoạt động như thể nó đã được đào tạo trên toàn bộ tập dữ liệu cùng một lúc.
Trường hợp sử dụng học tập liên hợp ban đầu là đào tạo các mô hình AI trên dữ liệu cá nhân được phân phối trên hàng tỷ thiết bị di động. Như các nhà nghiên cứu đó đã tóm tắt: “Các thiết bị di động hiện đại có quyền truy cập vào nhiều dữ liệu phù hợp với mô hình học máy …. Tuy nhiên, dữ liệu phong phú này thường nhạy cảm về quyền riêng tư, số lượng lớn hoặc cả hai, điều này có thể ngăn cản việc đăng nhập vào trung tâm dữ liệu …. Chúng tôi ủng hộ một giải pháp thay thế khiến dữ liệu đào tạo được phân phối trên các thiết bị di động và tìm hiểu mô hình chia sẻ bằng cách tổng hợp các bản cập nhật được tính toán cục bộ. ”
Gần đây, chăm sóc sức khỏe đã nổi lên như một lĩnh vực đặc biệt hứa hẹn cho việc áp dụng phương pháp học liên kết.
Rất dễ để hiểu lý do vì sao. Có rất nhiều trường hợp ứng dụng AI rất có giá trị trong lĩnh vực chăm sóc sức khỏe. Dữ liệu chăm sóc sức khỏe, đặc biệt là thông tin nhận dạng cá nhân của bệnh nhân, cực kỳ nhạy cảm; một tập hợp các quy định như HIPAA hạn chế việc sử dụng và di chuyển chúng. Học tập liên kết có thể cho phép các nhà nghiên cứu phát triển các công cụ AI chăm sóc sức khỏe, cứu sống bệnh nhân mà không cần chuyển hồ sơ sức khỏe nhạy cảm khỏi nguồn của chúng hoặc để lộ chúng với các vi phạm về quyền riêng tư.
Một loạt các công ty khởi nghiệp đã xuất hiện để theo đuổi việc học liên kết trong lĩnh vực chăm sóc sức khỏe. Được thành lập nhiều nhất là Owkin có trụ sở tại Paris; những người chơi ở giai đoạn trước bao gồm Lynx.MD, Ferrum Health và Secure AI Labs.
Ngoài chăm sóc sức khỏe, một ngày nào đó học tập liên kết có thể đóng vai trò trung tâm trong việc phát triển bất kỳ ứng dụng AI nào liên quan đến dữ liệu nhạy cảm: từ dịch vụ tài chính đến phương tiện tự hành, từ các trường hợp sử dụng của chính phủ đến các sản phẩm tiêu dùng các loại. Được kết hợp với các kỹ thuật bảo vệ quyền riêng tư khác như quyền riêng tư khác biệt và mã hóa đồng hình, học liên kết có thể cung cấp chìa khóa để mở ra tiềm năng to lớn của AI trong khi giảm thiểu thách thức khó khăn về quyền riêng tư dữ liệu.
Làn sóng luật bảo mật dữ liệu đang được ban hành trên toàn thế giới gần nay (bắt đầu với GDPR và CCPA, với nhiều luật tương tự sắp ra mắt) sẽ chỉ thúc đẩy nhu cầu về các kỹ thuật bảo vệ quyền riêng tư này. Mong đợi việc học tập liên kết sẽ trở thành một phần quan trọng của hệ thống công nghệ AI trong những năm tới.
Giới thiệu Workera – Nền tảng đánh giá kỹ năng AI của bạn
Workera là gì: Workera là nền tảng đánh giá kỹ năng của các nhà khoa học dữ liệu, kỹ sư học máy và kỹ sư phần mềm. Nó cung cấp phản hồi về hiệu suất, kế hoạch học tập, chứng nhận và giới thiệu đến các công việc AI tốt nhất. Workera hợp tác với các công ty trong các ngành để giúp họ thiết lập một nhóm AI hoạt động hàng đầu. Điều này bao gồm các nhóm kỹ thuật, khoa học ứng dụng và nghiên cứu trong Giáo dục, Sản xuất, Chăm sóc sức khỏe, Lái xe tự hành, Năng lượng, Giao thông vận tải, Người máy, Truyền thông xã hội, FinTech, Nông nghiệp, v.v.!
Cách tiếp cận của Workera là cá nhân hóa các kế hoạch học tập với các tài nguyên được nhắm mục tiêu – cả vai trò kỹ thuật và phi kỹ thuật – dựa trên mức độ thành thạo hiện tại của một người, do đó thu hẹp khoảng cách về kỹ năng.
Workera cung cấp một giải pháp cơ bản miễn phí cho các cá nhân muốn đạt được mục tiêu nghề nghiệp của họ. Đối với các tổ chức đang tìm cách chuyển đổi khả năng Dữ liệu-AI, Workera for Enterprise là giải pháp phù hợp.
Workera được thành lập vào năm 2020 bởi Katanforoosh và James Lee, COO, sau khi làm việc với Andrew Ng, người đồng sáng lập Coursera và là chủ tịch của Workera.
Tất cả chúng ta đều đã nghe nói về Machine Learning (học máy) và các ứng dụng đột phá của nó. Vì vậy, Machine Unlearning là gì và tại sao cần phải có nó? Vâng, trước tiên chúng ta hãy bắt đầu với sự hiểu biết cơ bản về ý nghĩa của nó. Học máy là một loại trí thông minh nhân tạo cho phép máy móc phân tích, học hỏi và thích ứng với môi trường xung quanh, điều này trước đó đã được thực hiện trên một tập dữ liệu hoàn toàn khác. Machine unlearning hoàn toàn ngược lại với nó. Thiết bị có thể giải phóng nội dung đã học bất cứ khi nào cần.
Machine Unlearning: SỰ CẦN THIẾT ĐỐI VỚI NÓ
Rất nhiều dữ liệu lớn bùng nổ trong các tổ chức và dữ liệu này giúp các thuật toán học máy học cách hoạt động trong môi trường mới. Tuy nhiên, đôi khi chúng tôi muốn hệ thống của mình không học các tài sản kỹ thuật số này vì một số lý do. Thứ nhất, việc lưu giữ dữ liệu liên tục dẫn đến các vấn đề về quyền riêng tư của dữ liệu. Tin tức gần đây trên Facebook đã nói lên tất cả – sự thay đổi trong chính sách quyền riêng tư để gửi thông tin của người dùng trên Web đã khiến người dùng mất lòng tin và cuối cùng họ đã xóa tài khoản của mình. Tương tự, sự cố Vi phạm dữ liệu iCloud đã khiến người dùng không hài lòng, khiến họ phải tìm kiếm các bài báo giảng dạy trực tuyến có thể giúp họ xóa dữ liệu của họ khỏi iCloud. Thứ hai, cùng với quyền riêng tư, việc đáp ứng ràng buộc bảo mật với việc học máy liên tục cũng là một thách thức lớn. Ví dụ: một hệ thống phát hiện bất thường, thường được dùng để phát hiện các cuộc xâm nhập, không thực hiện được công việc của nó với các kỹ thuật học máy. Hãy xem xét một tình huống mà kẻ tấn công đưa một số dữ liệu vào dữ liệu mẹ để gây ô nhiễm hệ thống. Điều gì sẽ xảy ra nếu hệ thống chấp nhận dữ liệu mới này làm dữ liệu của chính nó và thực hiện các tác vụ trong tương lai? Do đó, ở đây bảo mật không thành công. Trong trường hợp này, chúng tôi dường như muốn hệ thống quên dữ liệu bị ô nhiễm sau khi phát hiện và lấy lại bảo mật. Thứ ba, bạn có thể đã gặp phải tình huống Google gửi cho bạn tin tức hoặc cập nhật không quan trọng đối với bạn. Điều này xảy ra khi bạn hoặc bạn bè của bạn đã tìm kiếm chủ đề cụ thể đó và hệ thống biết rằng bạn quan tâm đến vấn đề cụ thể đó. Ở đây, chúng tôi muốn hệ thống không tìm hiểu và chỉ gửi tin tức hoặc khuyến nghị có liên quan cho bạn. Đây chỉ là một số lý do đã tạo ra nhu cầu về kỹ thuật Machine Unlearning.
Machine Unlearning: XÓA DỮ LIỆU KHÔNG MONG MUỐN NHANH CHÓNG
Các nhà nghiên cứu Yinzhi Cao và Junfeng Yang đã đề xuất một hệ thống có thể quên dữ liệu một cách hiệu quả. Mô hình dựa trên hai tiêu chí là tính đầy đủ và kịp thời. Tính đầy đủ có nghĩa là sự khác biệt giữa dữ liệu đào tạo và dữ liệu không được công bố, trong khi tính kịp thời liên quan đến việc hệ thống đã xóa sạch dữ liệu không cần thiết sớm như thế nào. Các nhà nghiên cứu đã thử nghiệm và chạy thành công mô hình này với các hệ thống học máy khác nhau. Sau thành công này, các nhà nghiên cứu hướng tới việc điều chỉnh kỹ thuật machine unlearning với các hệ thống khác và cuối cùng là xóa dữ liệu không mong muốn.
Không nghi ngờ gì nữa, các kỹ thuật học máy đã dẫn đến những đổi mới đáng kinh ngạc và đột phá nhưng chúng cũng dẫn đến một số vấn đề phải được giải quyết sớm nhất. Làm thế nào để sửa chữa chúng? Câu trả lời là machine unlearning.
Nhóm nghiên cứu của TS. Nguyễn Chí Tín (Đại học Nevada, Reno, Mỹ) đã phát triển được mô hình học sâu scCAN có khả năng phân cụm hàng triệu dữ liệu tế bào trong một thời gian ngắn với độ chính xác cao, nhờ đó có thể tìm ra những tế bào hiếm gặp trong mẫu sinh thiết ung thư một cách hiệu quả hơn.
Tìm lối đi giữa mênh mông dữ liệu
Sự phát triển của công nghệ là một điều mà có lẽ đa phần chúng ta đều mong muốn. Tuy nhiên, sự tiến bộ ấy đôi khi lại dẫn đến một “rắc rối” không nhỏ: số lượng dữ liệu sinh ra sẽ vượt quá khả năng xử lý của con người hay các công cụ hiện có. Và thực tế ấy càng thể hiện rõ nét hơn trong những lĩnh vực còn tương đối mới, ví dụ như công nghệ giải trình tự đơn tế bào (single-cell RNA sequencing).
TS. Nguyễn Chí Tín – trưởng nhóm nghiên cứu.
Trước đây, trong suốt nhiều năm, công nghệ giải trình tự gene thông thường (bulk sequencing) chỉ cho ra dữ liệu biểu hiện gene (gene expression data) dưới dạng kết quả trung bình của toàn bộ các tế bào trong mẫu mô sinh học. Thế nhưng, với sự ra đời của công nghệ giải trình tự đơn tế bào – một công nghệ giải trình tự thế hệ mới được ứng dụng rộng rãi trong những năm gần đây, các nhà sinh học sẽ phải đối mặt với một lượng dữ liệu khổng lồ được sản sinh ra sau mỗi lần giải trình tự. “Đây là công nghệ cho phép phân tích biểu hiện gene của từng tế bào hiện diện trong mẫu để phát hiện ra các dòng tế bào hiếm. Ngày nay, trải qua nhiều cải tiến, số lượng tế bào được giải trình tự trong mỗi lần phần tích đã lên tới hàng triệu hoặc hàng chục triệu, thay vì chỉ một tế bào trong một lần phân tích như ngày xưa”, TS. Nguyễn Chí Tín cho biết.
Khúc mắc nằm ở chỗ, “từ hàng triệu tế bào như vậy, chúng ta cần phải phân loại được các tế bào thuộc vào nhóm nào và chức năng của chúng ra sao, từ đó thì các nhà sinh học mới có thể tìm hiểu từng tế bào một và đánh giá tác động của chúng”, TS. Tín cho biết. Song, hầu hết những công cụ phân cụm tế bào hiện nay đều không thể hoạt động với tập dữ liệu lớn như vậy hoặc cần rất nhiều thời gian xử lý, ngay cả với hai mô hình AI có tên SC3 và Seurat do những đại học hàng đầu thế giới như Đại học Cambridge, Harvard và Học viện công nghệ Massachusetts phát triển.
“Các phương pháp này đều phải dựa vào một công cụ của một bên thứ ba để giảm bớt chiều dữ liệu (dimensionality reduction) trước khi tiến hành phân cụm bằng các thuật toán cổ điển. Trong khi đó, hầu hết các công cụ để giảm chiều dữ liệu như vậy đều rất dễ bị ảnh hưởng bởi ‘nhiễu’ và sự đa dạng của các nguồn dữ liệu giải trình tự. Thế nên khi tiến hành phân cụm trên nhiều tập dữ liệu khác nhau, các mô hình này đều không đảm bảo được độ chính xác ổn định”, TS. Tín phân tích. “Đó là lý do việc phát triển một công cụ mới có thể phân cụm hàng triệu tế bào trong một thời gian ngắn với độ chính xác cao là điều thực sự cần thiết cho các nhà nghiên cứu sinh học”, TS. Tín nhớ lại lý do bắt tay vào phát triển mô hình mới.
Nhận thấy các phương pháp truyền thống trước đây chỉ sử dụng một mô hình học sâu để xử lý “nhiễu” – một trong những điểm thách thức lớn nhất của bài toán và là hạn chế của các mô hình cũ, nhóm của TS. Tín đã quyết định thử sử dụng đồng thời ba mô hình để giải quyết vấn đề. “Trở ngại lớn nhất của phương pháp kết hợp đồng thời ba mô hình như vậy là khả năng tái lập kết quả phân cụm”, TS. Tín nói, “bởi vậy nhóm đã tiến hành tinh chỉnh sâu vào mã nguồn của thư viện xây dựng mô hình học sâu để đảm bảo rằng kết quả phân cụm cuối cùng là đồng nhất trên nhiều nền tảng tính toán”.
Vượt trội so với các mô hình trước
Sau quãng thời gian dài nghiên cứu với tiền đề là một thuật toán được nhóm xây dựng thành công từ năm 2021, TS. Tín và các cộng sự đã phát triển được một mô hình trí tuệ nhân tạo mới có tên scCAN. Đây là một công cụ phân cụm không giám sát (unsupervised) được xây dựng dựa trên nền tảng của công nghệ học sâu, mà cụ thể hơn là bộ tự mã hóa, thuật toán Spectral Clustering (sử dụng thông tin từ các giá trị riêng của các ma trận đặc biệt) và phương pháp lấy mẫu. Kết quả nghiên cứu này mới đây đã được công bố trong bài báo “scCAN: single-cell clustering using autoencoder and network fusion” trên tạp chí Scientific Reports.
So sánh khả năng xử lý của các mô hình.
Không giống các phương pháp truyền thống trước đây, công cụ scCAN sẽ sử dụng hai bộ tự mã hóa khác nhau để tiến hành lọc nhiễu và giảm chiều dữ liệu, trong đó mô hình sẽ loại bỏ những gene không quan trọng và giữ lại 5,000 gene mang nhiều thông tin. “Ở bước này, dữ liệu sau khi lọc nhiễu vẫn có chiều khá lớn. Do đó, scCAN tiếp tục dùng thêm một bộ tự mã hóa để tiếp tục giảm yếu tố này xuống mà không làm mất mát những thông tin quan trọng và cần thiết cho việc phân cụm tế bào”, nghiên cứu sinh Trần Sỹ Bằng – tác giả thứ nhất của nghiên cứu – cho biết. “Phương pháp này đã được ứng dụng rộng rãi trong mảng xử lý ảnh số và cho thấy có hiệu quả cao trong việc xử lý nhiễu. Thế nên việc ứng dụng mô hình này trong scCAN có thể giúp xử lý triệt để sự ảnh hưởng của nhiễu dữ liệu tới kết quả phân cụm – điều mà các phương pháp trước đây chưa làm được”, anh lý giải.
Để giải quyết vấn đề dữ liệu quá lớn, scCAN sử dụng phương pháp lấy mẫu (chọn ngẫu nhiên một lượng tế bào nhỏ để phân cụm trước và tiến hành gán nhãn), rồi sau đó mới xử lý những tế bào chưa được phân cụm còn lại dựa vào “khoảng cách” của chúng tới các nhóm đã phân loại thành công. “Cách làm này giúp đảm bảo mô hình AI của chúng tôi vẫn xử lý nhanh chóng, ngay cả khi tập dữ liệu có nhiều hơn một triệu tế bào”, anh Bằng cho biết. Nhằm kiểm tra khả năng phân cụm của mô hình, nhóm nghiên cứu đã sử dụng 243 tập dữ liệu mô phỏng và 28 tập dữ liệu thực tế thu thập từ nhiều nguồn khác nhau như tế bào não, máu, phổi. Khi so sánh với các phương pháp khác, mô hình của nhóm TS. Tín thể hiện ưu điểm vượt trội cả về khả năng và tốc độ xử lý khi scCAN có thể phân loại chính xác hàng triệu dữ liệu trong thời gian chưa đầy một tiếng đồng hồ.
Với những người ngoài ngành, mô hình phân cụm tế bào của nhóm TS. Tín nghe có vẻ khá xa lạ. Nhưng thực ra, nó ngầm ẩn trong đó những ứng dụng mà có thể đem lại lợi ích cho hàng ngàn người không may mắc phải những căn bệnh hiểm nghèo. Dưới góc nhìn của một nhà khoa học về tin sinh, “công trình này sẽ có ý nghĩa rất lớn trong việc tạo nền tảng cho các nghiên cứu sau này, điển hình là việc phân loại bệnh nhân ung thư và dự đoán rủi ro dựa trên dữ liệu gene”, TS. Tín nhận định.
Anh dẫn ví dụ, ngay cả trong cùng một nhóm bệnh nhân bị ung thư vú thì những người này vẫn có thể mắc bệnh theo bốn loại khác nhau. “Mỗi loại lại có mức độ di căn riêng và có thể điều trị bằng nhiều phương pháp mà không nhất thiết phải dùng hóa trị. Tuy nhiên hiện nay việc chẩn đoán đúng và tiên lượng thuốc vẫn cực kỳ phức tạp, hầu hết các bệnh nhân đều được khuyên sử dụng hóa trị hoặc yêu cầu cắt bỏ một hoặc hai bên ngực để tránh nguy cơ di căn, trong khi đáng lẽ ra có những người có thể được điều trị dứt điểm bằng các phương pháp ít xâm lấn hơn”, nhóm nghiên cứu cho biết.
“Do đó, dựa vào dữ liệu giải trình tự đơn tế bào và khả năng phân cụm chính xác của công cụ scCAN, chúng ta có thể tìm ra những tế bào hiếm gặp trong mẫu sinh thiết ung thư để kiểm nghiệm xem nhóm gene nào là tác nhân đóng góp vào việc phát triển bệnh, từ đó phân loại được bệnh nhân và đưa ra phác đồ điều trị thích hợp”, TS. Tín chia sẻ về những triển vọng tương lai.
Nhóm nghiên cứu của anh cũng đã nhận được các khoản tài trợ tổng cộng hơn 8 triệu USD từ Quỹ Khoa học Quốc gia Hoa Kỳ (NSF), Viện Y tế Quốc gia Hoa Kỳ (NIH) và Cơ quan Hàng không và Vũ trụ Quốc gia (NASA) cho dự án nghiên cứu kéo dài nhiều năm nhằm ứng dụng phương pháp học máy để nâng cao hiệu quả chẩn đoán y tế. Anh cũng hợp tác với các nhà nghiên cứu ở Viện VinBigdata (Việt Nam) để thực hiện các nghiên cứu tương tự. “Và việc lựa chọn được phương pháp điều trị chính xác như vậy sẽ giúp giảm cả chi phí chăm sóc sức khỏe lẫn sự đau đớn cho người bệnh”, TS. Tín nói.
Trong những năm gần đây, trí tuệ nhân tạo đã trở thành một ngành thời thượng. Các ứng dụng liên quan cung cấp cho con người những tiện ích vượt trội mà chỉ vài năm trước tưởng chừng không thể nào tồn tại. Iphone cho phép mở khóa điện thoại bằng nhận dạng khuôn mặt. Youtube gợi ý phim theo sở thích. Chương trình chơi cờ vây vượt mặt con người. Tất cả tạo nên ánh hào quang xung quanh một công nghệ mới.
Mặc dù vậy, trí tuệ nhân tạo vẫn còn là một công nghệ khó hiểu đối với số đông. Đa phần các sách chuyên ngành tập trung vào việc truyền tải kiến thức cho kỹ sư phần mềm để đáp ứng nhu cầu nhân lực trước mắt. Ngược lại, báo chí và truyền thông đã ít nhiều đề cập tới nhưng vẫn chưa đủ sâu sắc và hoàn chỉnh. Nhiều độc giả cần tìm hiểu thêm về công nghệ mới thì không có nguồn để tham khảo. Đó là lý do cuốn sách này ra đời.
Đối tượng độc giả của cuốn sách này là tất cả bạn đọc quan tâm tới trí tuệ nhân tạo nhưng không nhất định phải trở thành nhà nghiên cứu chuyên nghiệp. Cuốn sách được viết theo phong cách đơn giản để có thể truyền tải hiệu quả những công nghệ liên quan. Ngoài ra, trong tình hình nước ta đang phát triển mạnh mảng kinh tế tri thức và trí tuệ nhân tạo là một mũi nhọn, tác giả hi vọng có thể góp phần giúp các nhà làm chính sách có thêm một kênh tiếp cận công nghệ mới thông qua quyển sách này.
[Tại sao lại có nhiều tên gọi: Khoa Học Dữ Liệu (Data Science), Học Máy (Machine Learning), Trí Tuệ Nhân Tạo (AI), Thống Kê (Statistics)]
Ngày nay, chúng ta dễ dàng bắt gặp được những từ như Khoa Học Dữ Liệu, Học Máy, Trí Tuệ Nhân Tạo, và Thống Kê khi nói về dữ liệu và nói về những “thành tựu” mà con người đạt được trong thời gian gần đây trong mô phỏng trí thông minh con người. Vậy thực sự tại sao lại có nhiều tên gọi vậy?
Là một người từng được học và làm về nhiều lĩnh vực (education lúc undergrad là Toán, lúc Phd là Data Science và Stats, lúc làm sau tiến sĩ là Machine Learning và AI, và hiện tại khi làm giáo sư là làm về các lĩnh vực trên), ad cũng muốn đưa cho bạn một góc nhìn tổng thể một chút về sự giống nhau và khác biệt của các ngành trên:
— Khoa Học Dữ Liệu (Data Science) và Thống Kê (Statistics): Theo ad biết, từ này được Google tạo ra gần đây và quảng cáo để mọi người biết đến tầm quan trọng của dữ liệu trong đời sống. Về cơ bản, Data Science là re-name của một ngành học lâu đời hơn, Thống Kê (Statistics); tuy nhiên đó là một tên chỉnh chu hơn và giúp chúng ta hiểu rõ hơn bản chất của ngành học: “Làm việc và hiểu về bản chất của dữ liệu”.
Về cơ bản, Khoa Học Dữ Liệu và Thống Kê xây dựng nền tảng cho các khái niệm quan trọng chúng ta sử dụng ngày nay khi sử dụng và học dữ liệu, chẳng hạn như kỳ vọng (expectation), phương sai (variance), maximum likelihood estimation (MLE), etc.
Điểm nhấn của Khoa Học Dữ Liệu và Thống Kê truyền thống là về mặt suy diễn (inference), tức là làm sao chúng ta có thể hiểu được tính chất của mô hình, hiểu được khoảng tin cậy của kết quả, hiểu được cách thiết lập những hypothesis testing tin cậy dùng trong thực tiễn, etc.
Một điểm yếu của Khoa Học Dữ Liệu và Thống Kê truyền thống là về mặt tính toán. Hầu hết, các công cụ của các mảng này trước thời kỳ Deep Learning chỉ thiên về mặt suy diễn (inference) và bỏ quên đi mặt tính toán (computation); điều này, cũng dẫn đến nhiều vấn đề khi sử dụng các công cụ từ các mảng này cho dữ liệu hiện tại, vốn dĩ large-scale và high dimension.
— Học Máy (Machine Learning): Chúng ta có thể coi học máy là computational Data Science và Statistics, tức là học máy lấp đầy khoảng trống về mặt computation của Data Science và Statistics. Điểm nhấn quan trọng của học máy là về mặt prediction (dự đoán), tức chúng ta chỉ quan tâm đến label của dữ liệu là gì (mà không cần quan tâm đến độ tin cậy của dự đoán). Ngày nay, học máy tập trung vào việc đưa các khái niệm bên Data Science và Thống Kê, vào các vấn đề thời sự hiện tại của dữ liệu, như Fairness (tính công bằng), Privacy (tính bảo mật), Interpretability (tính diễn giải), etc.
Có thể nói, Học Máy, Khoa Học Dữ Liệu, và Thống Kê bù trừ khiếm khuyết cho nhau. Nếu bạn có thể hiểu được rõ sự tương tác giữa các ngành này, bạn đã có thể tự tin nói rằng mình hiểu về cách xây dựng mô hình và phương pháp với độ tin cậy nhất định khi làm với dữ liệu.
— Trí Tuệ Nhân Tạo (AI): AI là một mảng lớn và nó gồm nhiều mảng nhỏ, chẳng hạn như DS, ML, Stats. Đồng thời, nó cũng bao gồm cả thị giác máy tính (Computer Vision), Natural Language Processing (NLP), etc. Điểm nhấn của AI là làm sao có thể mô phỏng được trí thông minh của con người tốt nhất có thể (bằng bất cứ công cụ gì).
— Chung lại, do có quá nhiều sự trùng lặp giữa các mảng này mà chúng ta nhiều khi sử dụng nhiều tên gọi khác nhau. Tuy nhiên, mình muốn các bạn hiểu rằng, cho dù “label” của ngành học bạn là gì, mục đích cuối cùng là hiểu về dữ liệu và dùng nó để giúp máy tính make better and trustworthy decision (vốn dĩ giống với cách con người chúng ta tiếp cận thông tin và make the decision).
Mặc dù không thiếu các giải pháp học máy áp dụng cho hoạt động của một công ty, nhưng Digital Marketing (tiếp thị số) đã sẵn sàng để thu được nhiều lợi ích nhất từ ML (Machine Learning). Các công ty ngày nay thu thập vô số điểm dữ liệu về hành vi của khách hàng và mọi thứ từ số lượt thích trên trang truyền thông xã hội của một thương hiệu đến lượng thời gian khách hàng nhấp vào ‘đặt hàng’ đều có thể được ghi lại và phân tích.
Trong bài viết này, chúng tôi thảo luận về cách các tổ chức có thể sử dụng máy học trong tiếp thị kỹ thuật số để tìm kiếm khách hàng mới, hợp lý hóa phân khúc người tiêu dùng và làm cho trải nghiệm của khách hàng được cá nhân hóa hơn.
Tìm kiếm khách hàng mới
Lượng dữ liệu khổng lồ mà mọi người tạo ra trực tuyến hàng ngày là mỏ vàng của mọi nhà tiếp thị. Tất cả các loại nội dung mà mọi người đăng, thích, chia sẻ, tìm kiếm và tương tác có thể giúp các nhà tiếp thị xác định những người tiêu dùng có nhiều khả năng mua một loại sản phẩm hoặc dịch vụ cụ thể trong tương lai gần nhất.
Trong khi đó, công cụ xử lý ngôn ngữ tự nhiên kết hợp với giải pháp thị giác máy tính có thể tự động phát hiện chủ đề nào mà một khách hàng cụ thể quan tâm nhất.
Trên thực tế, đây chính xác là cách Chiến dịch ứng dụng của Google hoạt động. Mô hình học máy độc quyền phân tích vô số hành động mà người dùng thực hiện trực tuyến và hiển thị quảng cáo của thương hiệu cho những người dùng có nhiều khả năng mua hàng nhất. Hơn nữa, mô hình ML của Google cũng chăm sóc các thiết kế và định dạng quảng cáo ứng dụng. Các công ty chỉ cần cung cấp văn bản, video, hình ảnh và nội dung HTML5 có liên quan và ML sẽ tìm ra cách kết hợp tốt nhất cho một quảng cáo. Google thực hiện điều này bằng cách tự động thử nghiệm các thiết kế quảng cáo khác nhau trên Google Play, Google Tìm kiếm, Khám phá và YouTube để tiết lộ những thiết kế quảng cáo cụ thể nào hoạt động tốt nhất.
Cải thiện phân khúc cơ sở khách hàng
Phân khúc khách hàng là một trong những phương pháp lâu đời nhất và hiệu quả nhất cho phép các nhà tiếp thị giảm chi phí mỗi chuyển đổi (cost per acquisition – CPA) và tăng ROI. Thông thường, các nhà tiếp thị nhóm khách hàng chủ yếu dựa trên độ tuổi, vị trí, thu nhập, lựa chọn lối sống, sở thích và các đặc điểm có thể xác minh trực quan khác. Nhưng ML có thể giúp các nhà tiếp thị nhóm các thuộc tính của khách hàng không có ý nghĩa ngay từ cái nhìn đầu tiên.
Điều này được thực hiện với sự trợ giúp của các thuật toán ML không giám sát (unsupervised), có thể tìm thấy các mẫu trong dữ liệu không được gắn thẻ. Nói một cách thô thiển, bạn có thể ném một tập dữ liệu khổng lồ vào một thuật toán ML không giám sát và nó sẽ tự động tìm những điểm tương đồng giữa các khách hàng khác nhau và phân cụm họ thành các phân khúc. Đầu tiên, giải pháp có thể giảm đáng kể thời gian cần thiết cho việc phân khúc khách hàng. Thứ hai, nó cho phép tiết lộ các mối quan hệ ẩn giữa những khách hàng và nhóm khách hàng dường như không liên quan.
Tăng cường cá nhân hóa
Cá nhân hóa đã là một chủ đề nóng trong bối cảnh tiếp thị trong thập kỷ qua. Các nhà tiếp thị đã đạt được mức độ thành công khác nhau với cách tiếp cận dựa trên quy tắc để cá nhân hóa, tuy nhiên, khi đối tượng mục tiêu mở rộng cùng với một loạt các sản phẩm cung cấp, thì việc cá nhân hóa ngày càng trở nên khó đạt được. Quan trọng nhất, nhu cầu và mong muốn của khách hàng thường xuyên biến động, điều này làm cho các phương pháp tiếp cận thủ công để cá nhân hóa không hiệu quả trong dài hạn.
ML phần nào loại bỏ nhu cầu cấu hình thủ công các chiến lược cá nhân hóa và cho phép các công ty đạt được sự cá nhân hóa trên quy mô lớn. Với sự trợ giúp của tính năng lọc cộng tác và dựa trên nội dung, các tổ chức có thể tiết kiệm rất nhiều thời gian để tìm ra những sản phẩm sẽ cung cấp trong bản tin email tiếp theo của họ hoặc sau khi khách hàng mua một sản phẩm trong một danh mục cụ thể. Từ việc tạo nội dung đến các công cụ đề xuất, ML cho phép các nhà tiếp thị gia tăng lòng trung thành với thương hiệu và thúc đẩy sự gắn bó lâu dài của khách hàng.
Dự báo chu kỳ và nhu cầu
Sử dụng ML, các công ty có thể dự đoán nhu cầu và xác định lý do khiến khách hàng rời bỏ. Trong khi dự báo nhu cầu thường gắn liền với quản lý tài chính, những hiểu biết sâu sắc như vậy được chứng minh là có lợi cho việc cải thiện các chiến dịch tiếp thị. Biết những sản phẩm nào sẽ được quan tâm cao tại một thời kỳ cụ thể có thể giúp các nhà tiếp thị thúc đẩy nhiều chuyển đổi hơn.
Mô hình ML cũng có thể phát hiện các mẫu trong hành vi của khách hàng và giúp các doanh nghiệp hiểu được lý do đằng sau sự gián đoạn. Bằng cách này, các nhà tiếp thị có thể sử dụng ML để hiểu những gì khách hàng có khả năng hủy đăng ký nhận bản tin hoặc hủy đăng ký nhất và nhắm mục tiêu họ với các ưu đãi và khuyến mãi đặc biệt.
Hơn nữa, đối với phần lớn các công ty, có được một khách hàng mới tốn kém hơn nhiều so với việc giữ chân một khách hàng hiện tại. ML cho phép dự đoán giá trị lâu dài của khách hàng, cho phép các nhà tiếp thị đảm bảo rằng những khách hàng có giá trị nhất có xác suất bỏ cuộc ít nhất trong dài hạn.
Kết luận
Các ví dụ nêu trên về các ứng dụng ML trong tiếp thị số chỉ đang làm xước bề mặt của tiềm năng thực sự của công nghệ. Tóm lại, ML cho phép các nhà tiếp thị liên tục phân tích một luồng dữ liệu khổng lồ liên tục được tạo ra bởi người tiêu dùng trong quá khứ, hiện tại và tương lai của nó.
Tại thời điểm này, việc bỏ qua tiếp thị dựa trên ML chắc chắn sẽ dẫn đến bất lợi cạnh tranh trong tương lai. Khi khách hàng nhận ra rằng họ cần mua một sản phẩm cụ thể, các nhà tiếp thị sử dụng ML có thể xác định khách hàng tiềm năng đó nhanh hơn nhiều so với những người không sử dụng. Từ đó, các thương hiệu khác nhau sẽ cạnh tranh với nhau dựa trên thời gian và thiết kế quảng cáo của họ, điều này cũng nhanh chóng trở thành một trong những chuyên môn của ML. Bằng cách này, khi công nghệ tiếp tục phát triển, lợi thế cạnh tranh tiếp thị trở nên phụ thuộc nhiều hơn vào trình độ khai thác ML của công ty.
Trên thực tế, việc tích hợp sâu rộng ML như vậy vào các hoạt động tiếp thị còn phải đi trước nhiều năm, vì vẫn còn chỗ để công nghệ cải tiến và các quy định bắt kịp. Tuy nhiên, những người đang khám phá các chiến lược dựa trên ML sẽ có lợi thế rõ ràng khi công nghệ này sẽ trở nên phổ biến trong bối cảnh tiếp thị.
Trong thập kỷ qua, ứng dụng công nghệ trí tuệ nhân tạo AI (Artificial Intelligence) đã và đang phát triển mạnh. Đặc biệt là ứng dụng AI trong điện toán đám mây (ĐTĐM) (Cloud computing) được các doanh nghiệp (DN) trên thế giới sử dụng để chuyển đổi số (CĐS) rất thành công.05/07/2021 – 15:53
Ứng dụng AI trong nhiều lĩnh vực đạt được thành công nhất có thể kể đến như: bán lẻ, tài chính, sản xuất, nông nghiệp, giáo dục, ô tô, bán hàng B2B, ngân hàng, thương mại, bảo hiểm, khoa học đời sống và các dịch vụ tiện ích. AI đã giúp nhiều DN hoạt động trong lĩnh vực này thực hiện chuyển đổi số thành công với chi phí thấp, hiệu quả, sản xuất tự động nhiều hơn. Song song với các cơ hội mà AI mang lại thì AI cũng đem lại những thách thức không nhỏ đối với nhà quản lý DN.
Ứng dụng AI trong hầu hết mọi lĩnh vực
Cuộc cách mạng 4.0 hiện nay đã cho thấy công nghệ nhanh chóng trở nên thông minh hơn và mạnh hơn, nhỏ hơn, nhẹ hơn và rẻ hơn. Các công nghệ này bao gồm phần cứng của các thiết bị: robot vật lý, máy bay không người lái và phương tiện tự trị và các thành phần của chúng (ví dụ: bộ xử lý, cảm biến, camera, chip). Công nghệ có thể là mã hoặc phần mềm như: phần mềm Analytics, phần mềm xử lý giọng nói, phần mềm sinh trắc học, thực tế ảo, thực tế tăng cường, công nghệ đám mây, công nghệ di động, gắn thẻ địa lý, nền tảng mã thấp, tự động hóa quá trình robot (RPA) và học máy. AI sẽ làm thay đổi tất cả các ngành trong tất cả các lĩnh vực dịch vụ và tự động hóa như:
Trong quản lý nhân sự: AI kiểm soát quá trình lao động tại nơi làm việc, cho phép tối đa hóa năng suất và hiệu quả của con người tại nơi làm việc. Theo một báo cáo gần đây, hầu hết các tổ chức lớn đã xây dựng khả năng của AI, 70% giám đốc điều hành xem ứng dụng AI ưu tiên hàng đầu. Năm 2020 là một năm thuận lợi để các công ty bán phần mềm giám sát nhân viên.
Ví dụ, giải pháp “Công nhân Maximo” của IBM sử dụng AI để xử lý dữ liệu thời gian thực từ “camera, tín hiệu Bluetooth, điện thoại di động, thiết bị đeo có kết nối IoT và cảm biến môi trường” cho phép người quản lý giám sát nhân viên hiệu quả. Ngoài ra, AI hứa cho phép dự đoán và ngăn chặn sự vi phạm của trật tự được thiết lập trước khi chúng xảy ra.
Trong DN: Theo Alibaba, Chatbot AI đã giúp họ giảm tới 90% truy vấn đối với khách hàng và phục vụ hơn 3,5 triệu người dùng mỗi ngày. Trong một nghiên cứu gần đây liên quan đến 1.500 công ty trong 12 ngành công nghiệp, đã cho thấy các tổ chức có thể đạt được những cải tiến hiệu suất đáng kể nhất khi con người và máy móc làm việc cùng nhau.
Ví dụ, chatbot của chương trình Chương trình Thạc sĩ quản trị kinh doanh của Đại học Quốc gia Singapore (NUS MBA) đã xử lý 20.000 cuộc hội thoại mỗi tháng ngay sau khi khởi chạy và trả lời tất cả các câu hỏi thường ngày. Còn theo Google, hệ thống khuyến nghị AI Google đã giúp tiết kiệm năng lượng khoảng 30% tại các trung tâm dữ liệu của họ. Công nghệ robot có thể tăng cường khả năng trong việc kiểm tra hàng hóa. Công ty cũng có thể dùng AI để cải thiện việc kiểm tra và bảo trì, hay kiểm soát trên các chuỗi cung ứng.
Trong phân tích dữ liệu: Dữ liệu rất quan trọng đối với các DN để thực hiện các giải pháp AI nhằm cải thiện khả năng kinh doanh của DN. Nếu được lập trình một cách thích hợp, AI có thể tìm kiếm cơ sở dữ liệu rộng lớn cho các danh mục và từ khóa được xác định trước có liên quan, cũng như xây dựng các đề xuất về cách thông tin được thu thập có thể bổ sung mới vào các sản phẩm và dịch vụ hiện có.
Do đó, AI tăng cường quá trình sáng tạo bền bỉ hơn con người, nó vượt trội hơn trong lưu trữ và xử lý thông tin, cũng như khi AI tham gia vào các quy trình tìm kiếm có hệ thống và gia tăng các bộ dữ liệu lớn. Dữ liệu có giá trị nhất hiện đang được kiểm soát bởi các DN lớn như Google, Facebook, Alibaba, Tencent, v.v.. Đây là lý do tại sao hầu hết các câu chuyện thành công nổi tiếng về ứng dụng AI đến từ những DN lớn này trong 10 năm qua. Các DN lớn này có những đóng góp đáng kể để đưa các giải pháp AI vào cuộc sống hàng ngày.
Trong y tế: Liên quan đến phát hiện ung thư, trong hình ảnh của các tế bào hạch bạch huyết, Wang et al. (2016) phát hiện ra rằng một cách tiếp cận con người kết hợp với AI sẽ vượt trội hơn so với các quyết định chỉ có con người duy nhất. Tỷ lệ lỗi 0,5% khi kết hợp AI và con người trong việc ra quyết định, giảm tỷ lệ lỗi ít nhất ở mức 85% so với các phương pháp tiếp cận chỉ có con người và chỉ có AI.
Triển vọng rất lớn khi ứng dụng AI trong các dịch vụ y tế, bao gồm chăm sóc sức khỏe có khả năng sẽ trở nên có giá thấp hơn nhiều và chất lượng tốt hơn nhiều, và dẫn đến sự gia tăng mạnh mẽ trong tiêu chuẩn sống của chúng ta. Không những thế, Robot dịch vụ so sánh dữ liệu và triệu chứng của bệnh nhân và cung cấp một “danh sách hit” có thể xảy ra với một chỉ số phù hợp. Các bác sĩ đa khoa sau đó có thể làm việc trong danh sách và thảo luận với bệnh nhân (ví dụ: “Bạn đã ở vùng nhiệt đới trong hai tuần qua chưa?”) Và sau đó xác định chẩn đoán và kiểm tra nhiều khả năng nhất cho nó.
Trong các ngành dịch vụ và tự động hóa: Robot dịch vụ có thể phân tích khối lượng dữ liệu lớn, tích hợp thông tin nội bộ và bên ngoài, nhận dạng các mẫu liên quan đến các hồ sơ khách hàng. Trong vài phút, các robot này có thể đề xuất các giải pháp phù hợp nhất và đưa ra khuyến nghị. Các đội người-robot ngày càng mang lại các nhiệm vụ đòi hỏi kỹ năng nhận thức và cảm xúc cao.
Ví dụ, trong bối cảnh chăm sóc sức khỏe, robot dịch vụ sẽ thực hiện công việc phân tích (phân tích các triệu chứng và so sánh chúng với cơ sở dữ liệu để chẩn đoán) và con người sẽ đưa ra các khuyến nghị và quyết định cuối cùng và đảm nhận các nhiệm vụ xã hội và cảm xúc (tư vấn và thuyết phục bệnh nhân).
Một robot bán vé sẽ không cho phép khách hàng bị mắc kẹt, vì nó có thể yêu cầu làm rõ các câu hỏi (“Chuyến đi trở về của bạn ngày hôm nay là chuyến nào?”, “Bạn có thể đi quá mức không?”) và thậm chí có thể khôi phục lỗi khách hàng (ví dụ: sai nhấn nút, thông tin không chính xác làm cho đăng nhập hoặc thẻ tín dụng bị từ chối). Đối với hầu hết các dịch vụ tiêu chuẩn, khách hàng sẽ tương tác với các robot dịch vụ theo cách tương tự như với nhân viên phục vụ (“Tôi cần một vé khứ hồi cùng ngày và tôi có thể sử dụng Zalo Pay không?”).
Amazon gần đây đã sử dụng một hệ thống theo dõi Warehouse-Worker (nhân viên kho hàng chịu trách nhiệm thực hiện một loạt các nhiệm vụ như tiếp nhận và xử lý kho và nguyên vật liệu nhập vào, chọn và điền đơn hàng từ kho, đóng gói và vận chuyển đơn đặt hàng, hoặc quản lý, sắp xếp và truy xuất kho hàng và các hoạt động khác) có thể tự động làm việc mà không có sự tham gia giám sát của con người. Ví dụ này cho thấy rằng quản lý thuật toán, nơi các thuật toán có một mức độ tự chủ nhất định khi đưa ra quyết định, đang tăng lên trong các tổ chức.
Trong ngành thương mại và du lịch: Trí thông minh nhân tạo đang thay đổi cách mà những người kinh doanh làm việc, giúp khả năng thương mại hiệu quả, ít tốn kém và cạnh tranh. Mục tiêu thương mại chủ yếu là sự tuân thủ và kiểm soát cẩn thận, như cách xử lý ngôn ngữ tự nhiên để tạo ra hồ sơ toàn diện của cá nhân hay DN tham gia giao dịch, dựa trên các khả năng tìm kiếm trên mạng Internet. Các ứng dụng tìm kiếm bất thường được ứng dụng AI.
Ví dụ sự khác biệt giữa giá cho mỗi đơn vị sản phẩm và giá trị hóa đơn cuối cùng. Thực hiện AI chắc chắn có giá trị, đặc biệt là phát triển những các ứng dụng điện tử đáng tin cậy, không cần văn bản giấy, kiểm tra danh tính (ID) nhanh hơn, chia sẻ dữ liệu và thủ tục lưu tài liệu theo tiêu chuẩn số hóa. Sự gia nhập của AI trong ngành thương mại sẽ yêu cầu phát triển một loạt các tiêu chuẩn mới, cho phép cải tiến quản lý kho hàng, dự đoán yêu cầu, và độ chính xác hơn trong việc chế tạo và vận chuyển đúng thời gian.
Anhr: CNTG
Có lẽ sự đột phá lớn nhất trong công nghệ AI Trung Quốc nằm trong lĩnh vực hệ thống thanh toán thương mại và du lịch thông qua nhận dạng khuôn mặt. Ở Trung Quốc, thẻ tín dụng không được dùng phổ biến, nhưng việc thanh toán không dùng tiền mặt vẫn phổ biến, thậm chí nhiều cửa hàng không lấy tiền mặt. Người tiêu dùng Trung Quốc có thể trả tiền cho hàng hóa tại các siêu thị, nhà hàng ăn nhanh, trạm xăng và các cửa hàng bán lẻ khác chỉ với điện thoại di động của họ. Công nghệ nhận dạng khuôn mặt xác định người dùng trong 100 mili giây hoặc một phần mười giây. Khuôn mặt của họ được liên kết với hệ thống thanh toán số của họ và hàng hóa được mua mà không cần tiếp cận túi hay ví.
Alibaba gọi là cười để thanh toán, còn WeChat sử dụng hệ thống có tên Frog Pro thông qua nhận dạng sinh trắc học qua tàn nhang, tĩnh mạch, nốt ruồi, nếp nhăn và các đặc điểm khác. Thuật toán sinh trắc học so sánh các bức ảnh với các chi tiết về khuôn mặt của một cá nhân bao gồm kích thước, hình dạng và vị trí của mắt, mũi, gò má và hàm. Sinh trắc học khác tập trung vào hình dạng cơ thể của một người và dáng đi, những chuyển động mà anh ta hoặc cô ta làm khi đi bộ. Hệ thống sinh trắc học ghi lại các đặc điểm này với các cảm biến 3 chiều. Với các phương pháp nhận dạng chính xác này, các nhà bán lẻ Trung Quốc đang kiếm tiền mà không cần thẻ tín dụng.
Trong công nghệ điện toán đám mây: Hệ thống Alibaba Cloud có thể giúp DN hoạt động hiệu quả. Trung tâm dữ liệu trí tuệ nhân tạo của Alibaba hoạt động trên nền tảng đám mây đã hỗ trợ gần 800 triệu người tiêu dùng và các nhà bán lẻ trên toàn thế giới cùng tham gia vào cuộc thi lớn nhất hành tinh. Đó là sự kiện về lễ hội mua sắm trực tuyến Alibaba Global (còn được gọi là “Ngày độc thân”). Có tới 583.000 đơn đặt hàng mỗi giây được hưởng trải nghiệm mua sắm từ phần mềm được hỗ trợ AI, cho phép khắc phục lỗi bảo trì theo thời gian thực.
Dựa trên nền tảng đám mây, Alibaba Cloud đã xử lý hàng triệu đơn đặt hàng cho công ty chuyển phát STO Express của Trung Quốc cho phép công ty này cắt giảm chi phí CNTT tới 30% và giảm thời gian đồng bộ dữ liệu từ một giờ xuống còn ba phút. Alibaba Cloud cũng cung cấp các ứng dụng trí tuệ nhân tạo AI cho phép DN có thể đưa ý tưởng hay các nghiên cứu và phát triển các giai đoạn mua sắm vào trong sản xuất.
Ví dụ: Công ty PrestoMall, hoạt động trong lĩnh vực thương mại điện tử lớn nhất Malaysia nhờ sử dụng dữ liệu trên đám mây của Alibaba Cloud cho phép công ty này tăng trưởng ấn tượng, giảm chi phí hơn 40% sau khi di chuyển dữ liệu lên đám mây. Tại Nhật Bản, một công ty trò chơi có tên là ENISH, tận dụng giải pháp chơi game của Alibaba Cloud bắt đầu hoạt động từ năm 2020. Bây giờ ENISH có thể xây dựng một môi trường thử nghiệm cho trò chơi mới chỉ trong 10 ngày so với 20 ngày như trước đây và có thể xây dựng tạo mô hình game trong vòng 7 ngày, đây là một kết quả ấn tượng kể từ khi công ty này sử dụng dịch vụ của Alibaba Cloud.
Trong tài chính ngân hàng: AI có thể giúp giám sát dữ liệu theo thời gian thực, phát hiện những điều kỳ lạ để điều tra thêm và loại bỏ hoặc giảm sự xuất hiện của gian lận trong thanh toán do tội phạm mạng chuyên nghiệp thực hiện. Gian lận thanh toán hiện nay tinh vi hơn và thường vượt quá khả năng phát hiện của các hệ thống dựa trên quy tắc cũ. Ứng dụng AI cho phép chống gian lận, bảo mật gấp đôi so với giải pháp bảo mật thông thường do vậy lừa đảo được phát hiện gần ngay lập tức và thông tin thông báo sẽ được gửi đi kịp thời.
Do các công ty AI đang cạnh tranh nhau để cung cấp giải pháp nhanh hơn, tỉ lệ ứng dụng cho việc tính toán rủi ro đang tăng dần. Phân tích AI và kết hợp kĩ sư AI có thể tìm ra sự khác biệt trong các bộ dữ liệu lớn chỉ trong vài giây giúp nhân viên ngân hàng phân biệt lừa đảo và đúng luật pháp với độ chính xác hơn. Công nghệ Blockchain tích hợp AI có khả năng có thể được sử dụng để xây dựng một thị trường hợp tác, cho phép các DN vừa và nhỏ có thể hợp tác để vượt qua những thách thức về dữ liệu và tài năng và phát triển các giải pháp AI thành công.
Mới đây, tạp chí The Economist Intelligence Unit đã công bố báo cáo phân tích kết quả từ một cuộc khảo sát 200 giám đốc điều hành kinh doanh và các nhà quản lý cấp cao liên quan đến CNTT. Chủ đề là “Khảo sát công nghệ trí tuệ nhân tạo (AI) được ứng dụng trong ngành dịch vụ tài chính”, mục đích là đo lường sự thành công của AI, cơ hội và thách thức của các công nghệ AI này trong tương lai. Thông qua khảo sát và các cuộc phỏng vấn sâu với các chuyên gia hàng đầu trong lĩnh vực AI để xác định cách những thay đổi sẽ định hình trong ngành tài chính trong những năm tới. Kết quả là:
• Nhiều ngân hàng, các nhà bán lẻ và các công ty bảo hiểm đang bắt đầu khảo sát các xu hướng ứng dụng AI làm sao cho hiệu quả. Do quy mô của AI, các ngân hàng đang vật lộn với một số thách thức về mức độ phức tạp và về quy mô lớn. Việc ứng dụng công nghệ tiên tiến AI đã đem lại hiệu quả to lớn trong các ngành này.
• Tại khu vực châu Á – Thái Bình Dương (APAC) gần 61% người trong APAC được hỏi đã báo cáo rằng công việc của họ được AI hỗ trợ một nửa hoặc nhiều hơn. Trong khi ở Bắc Mỹ và châu Âu con số này là 41%.
• Một loạt ứng dụng được thực hiện bởi AI trong các ngân hàng và các công ty bảo hiểm như trợ lý ảo, học máy và phân tích dự đoán cùng với với việc xử lý ngôn ngữ tự nhiên NPL ở phía sau đã được sử dụng rộng rãi trong các danh mục “ứng dụng AI”.
• Mức độ hài lòng của khách hàng và các bên liên quan đã giúp AI thành công. Còn những người khác cho rằng ứng dụng AI chỉ để giảm chi phí vận hành và tăng lợi tức đầu tư là yếu tố quan trọng. Tuy nhiên, gần 10% số người được hỏi ở châu Âu không có số liệu để đo lường ứng dụng AI thành công.
• Hiệu quả của việc ứng dụng công nghệ AI này rất rõ ràng. Ví dụ, các nhiệm vụ thủ công trong những thập kỷ trước đây được thay bằng tự động hóa. Điều này đã dẫn đến một sự hợp lý hóa lực lượng lao động, với nhân sự có kỹ năng thực hiện các chức năng có giá trị cao hơn. Một lần nữa APAC dẫn đầu khu vực trong đầu tư vào các dự án có liên quan đến công nghệ AI.
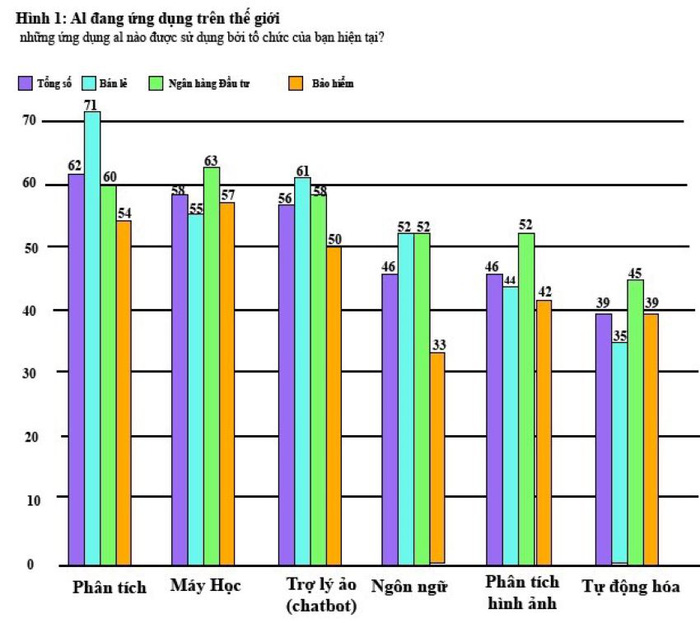
Hình 1: AI được ứng dụng. (Nguồn: The Economist Intelligence Unit)
Cơ hội
Rất nhiều CEO đều công nhận rằng AI có tiềm năng thay đổi hoàn toàn cách thức hoạt động của tổ chức. Để nắm bắt được cơ hội mà AI mang lại các DN cần hình dung lại mô hình kinh doanh của mình và phương thức hoạt động. DN không thể cứ ứng dụng AI vào một quy trình hiện tại để tự động hóa nó hoặc thêm thông tin chi tiết. Cách tiếp cận sử dụng AI qua các chức năng có trong danh sách ứng dụng cụ thể sẽ không đem lại thay đổi bởi vì nó phụ thuộc vào quy trình hoạt động DN.
Và cách tiếp cận đó cũng làm cho việc ứng dụng AI mở rộng quy mô, tăng thêm module lập trình liên quan đến dữ liệu đầu vào, dữ liệu đào tạo, dữ liệu thay đổi, dữ liệu quản lý đối tác và dữ liệu công nghệ. Điều đó không có nghĩa là DN nên thay đổi toàn bộ tổ chức khi ứng dụng AI cùng một lúc. Một sự thay đổi hoàn toàn là một quá trình cực kỳ phức tạp liên quan đến quá nhiều nhiều bộ phận và các bên liên quan. Thay đổi trong toàn bộ quy trình hoặc chức năng cốt lõi được gọi là miền quản lý sẽ dẫn đến cải tiến lớn về hiệu suất.
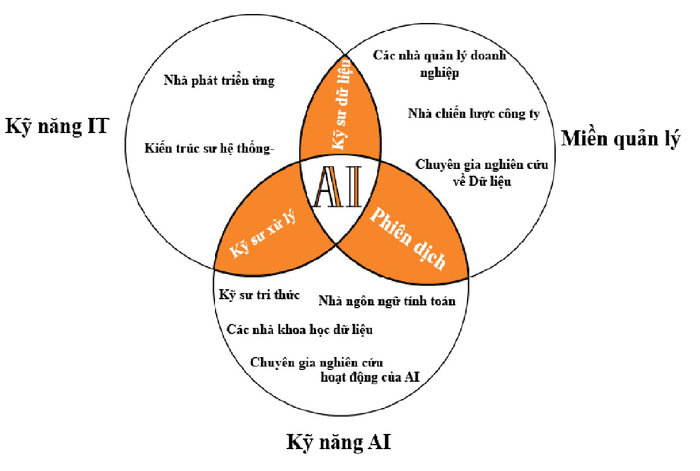
Không những thế, tập hợp một nhóm nhân tài phù hợp với các trường hợp cần giải quyết ba sự cân bằng lý tưởng để nắm bắt cơ hội AI và bắt đầu các nỗ lực AI. Những nhân sự trong ba hình tròn sẽ tạo thành bộ ba bổ sung về AI, CNTT và chuyên môn về miền quản lý. Nhưng trong mỗi lĩnh vực chuyên môn, các nhân sự có kỹ năng sẽ là trung tâm để giải quyết các trường hợp được đề xuất (xem Hình 2).
Hình 2: Dự án AI cần nhiều tài năng và kỹ năng. (Nguồn: Gartner)
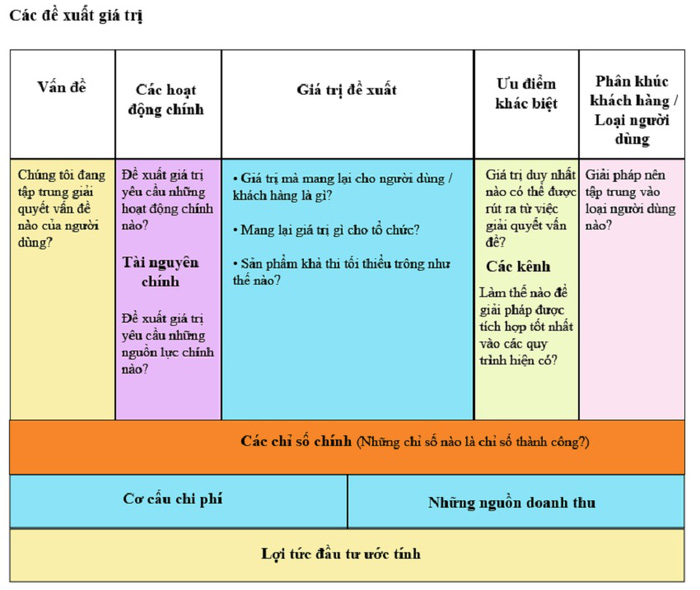
Nó cũng sẽ cho phép mỗi sáng kiến AI sử dụng lại dữ liệu hoặc cải tiến khả năng của các loại dữ liệu liên quan. Cách tiếp cận này kích hoạt một chu kỳ thay đổi hữu cơ trong nhiều lĩnh vực và cuối cùng là xây dựng động lực cho việc sử dụng AI trong toàn bộ DN. Hơn nữa, cách tiếp cận này thúc đẩy tư duy về cải tiến liên tục trong lực lượng lao động, điều này rất quan trọng vì công nghệ AI đang phát triển nhanh chóng, yêu cầu các tổ chức nghĩ về chuyển đổi AI liên tục thay vì nỗ lực chuyển đổi một lần. Không những thế, khi mô tả các trường hợp sử dụng AI càng rõ ràng càng tốt, đặc biệt khi nói đến các kỹ thuật AI, các đề xuất giá trị cần phải được trình bày rõ ràng nhất có thể. Một framework đề xuất giá trị như thể hiện trong Hình 3 có thể là một công cụ mạnh để các CIO đánh giá một cách minh bạch kết quả kinh doanh và các rào cản tiềm ẩn.
Cuối cùng, DN nào không thể tận dụng hết khả năng và cơ hội do AI mang lại sẽ bị gạt sang một bên, ví dụ như nhiều DN sản xuất ô tô và DN dịch vụ tài chính. Tin tốt là nhiều DN có số liệu phân tích hạn chế khả năng đã bắt đầu phát triển các kỹ năng cần thiết để nắm bắt các cơ hội AI, vì cuộc khủng hoảng COVID-19 đã buộc họ thay đổi cách họ kinh doanh gần như chỉ sau một đêm.
Hình 3: Các đề xuất giá trị trong dự án ứng dụng AI. (Nguồn: Gartner)
Thách thức
Thách thức ở đây là việc tự động hóa các quy trình làm việc bằng phương tiện AI đã làm tỷ lệ thất nghiệp tăng lên. Bởi vì AI giúp tự động hóa và xử lý các vấn để phức tạp và sáng tạo trong công việc nhờ áp dụng các thuật toán ML đã được tối ưu. AI sẽ dần thay thế công việc của con người ở những công việc có tính phức tạp và sáng tạo. Không những thế, chuyện gì xảy ra khi ML và các chương trình máy tính cập nhật thông tin mới và sau đó thay đổi cách chúng đưa ra quyết định, dẫn đến có sự thiên vị trong các khoản đầu tư, trong các khoản cho thuê hoặc cho vay hay trong tai nạn ô tô?
Thuật toán trong AI không phải lúc nào cũng hoạt động trơn tru và không phải lúc nào AI cũng đưa ra được lựa chọn có đạo đức và chính xác. Có ba lý do cơ bản là:
Thứ nhất, các thuật toán ML thường dựa vào xác suất. Nên khi các thuật toán trong AI đưa ra rất nhiều dự đoán thì có thể một trong số dự đoán đó sẽ sai. Khả năng xảy ra lỗi phụ thuộc vào rất nhiều yếu tố, bao gồm số lượng và chất lượng của dữ liệu được sử dụng để đào tạo các thuật toán ML, phương pháp ML được chọn (ví dụ: học sâu, sử dụng các mô hình toán học phức tạp, cây phân loại dựa trên các quy tắc quyết định) và hệ thống sử dụng các thuật toán. Khả năng xảy ra lỗi có thể không cho phép tối ưu hóa độ chính xác.
Thứ hai, môi trường mà ML hoạt động tự nó có thể phát triển hoặc phát triển các thuật toán khác. Mặc dù các khả năng này có thể xảy ra thì một trong số đó thường gặp nhất là bị mất khái niệm và dịch chuyển đồng biến. Theo thời gian, mối quan hệ giữa các đầu vào mà hệ thống sử dụng không ổn định hoặc không xác định. Ví dụ khi xem xét một thuật toán ML sử dụng trong giao dịch chứng khoán.
Nếu ML đã được đào tạo chỉ sử dụng dữ liệu trong thời kỳ thị trường ít biến động và tăng trưởng kinh tế cao, thuật toán ML có thể không hoạt động tốt khi nền kinh tế bước vào suy thoái hoặc khủng hoảng ví dụ như trong cuộc khủng hoảng từ đại dịch COVID-19. Khi thị trường thay đổi, mối quan hệ giữa các yếu tố đầu vào và đầu ra (ví dụ như giữa đòn bẩy lâu năm của một DN và lợi nhuận cổ phiếu của DN đó) cũng có thể thay đổi. Sự sai lệch tương tự có thể xảy ra ở mô hình tính điểm tín dụng tại các thời điểm khác nhau trong chu kỳ kinh doanh.
Trong y học, khi một hệ thống chẩn đoán dựa trên ML sử dụng hình ảnh màu da làm đầu vào trong việc phát hiện ung thư da có thể chẩn đoán không chính xác là bởi vì mối quan hệ giữa màu sắc của da có thể thay đổi theo chủng tộc hoặc tiếp xúc với ánh nắng mặt trời. Quyết định chẩn đoán sai này là do thông tin để các thuật toán ML tự học là không chính xác và không đầy đủ. Thông tin như vậy thậm chí không có sẵn trong hồ sơ sức khỏe điện tử được sử dụng để đào tạo mô hình ML, trong quá trình sử dụng khác với dữ liệu mà AI được đào tạo.
Thứ ba, là các quyết định của ML làm tăng tính phức tạp của hệ thống. Khi xem xét một thiết bị dùng để chẩn đoán bệnh qua hình ảnh. Chất lượng thiết bị phụ thuộc vào: thứ nhất là độ nét của hình ảnh, thứ hai là thuật toán ML được thiết bị sử dụng, thứ ba là dữ liệu mà thuật toán đó đào tạo cho ML. Với rất nhiều thông số, rất khó để đánh giá liệu và tại sao một thiết bị như vậy có thể phạm sai lầm. Các quyết định thiếu chính xác không phải là rủi ro duy nhất mà AI có thể tạo ra.
Rủi ro AI
Sự không hoàn hảo của công nghệ ML làm dấy lên một thách thức khác: Rủi ro bắt nguồn từ những thứ không đúng sự kiểm soát của DN hay tổ chức. Vì ML thường được nhúng vào hệ thống phức tạp, nó sẽ không phân tích rõ ràng nhà phát triển thuật toán, người triển khai hệ thống hay đối tác chịu trách nhiệm về một lỗi và liệu thuật toán có sự cố, với một số dữ liệu được người dùng cung cấp cho nó hoặc với dữ liệu được sử dụng để đào tạo nó, có thể đến từ nhiều bên thứ ba cung cấp. Sự thay đổi môi trường và bản chất mạnh mẽ của công nghệ ML khiến việc quy trách nhiệm cho một tác nhân cụ thể càng khó hơn.
Trên thực tế, tai nạn hoặc các quyết định trái pháp luật có thể xảy ra ngay cả khi không có sơ suất gì. Vì đơn giản là luôn có khả năng xảy ra quyết định không chính xác. Các giám đốc điều hành cần biết khi nào công ty của họ có khả năng phải đối mặt với trách nhiệm pháp lý hiện hành do ứng dụng công nghệ AI gây ra.
Các sản phẩm và dịch vụ tự đưa ra quyết định cũng sẽ cần giải quyết các tình huống khó xử về đạo đức. DN cần cân bằng giữa quyền riêng tư, sự công bằng, độ chính xác và bảo mật? Có thể tránh được tất cả các loại rủi ro không? Rủi ro đạo đức bao gồm các thành kiến liên quan đến nhân khẩu học các nhóm. Ví dụ: các thuật toán nhận dạng khuôn mặt có một thời gian rất khó để xác định người da màu. Khi sử dụng AI trong thương mại, hệ thống ML có thể được coi là không công bằng đối với một nhóm nhất định ở một khía cạnh nào đó. Cuối cùng, tất cả các vấn đề này cũng có thể do mô hình gây ra không ổn định. Đây là tình huống mà các đầu vào gần nhau dẫn đến những quyết định khác xa nhau.
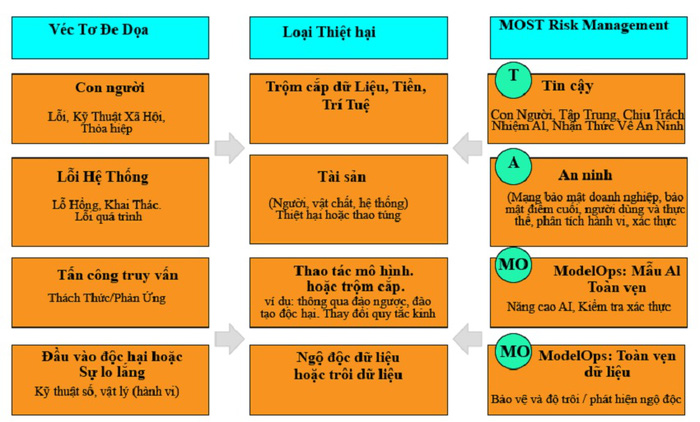
Để có thể phòng chống rủi ro AI, DN cần áp dụng framework quản lý rủi ro của Gartner (Hình 4) mô tả vấn đề bảo vệ các hệ thống và giải pháp dựa trên AI, với sự tập trung vào MLe và những thách thức liên quan đến bảo mật, tính toàn vẹn và tính khả dụng ở mỗi giai đoạn. Nó cũng mô tả một số thách thức của các hệ thống AI bao gồm thiên vị, đạo đức và khả năng giải thích. Một số phương thức tấn công khác và thiệt hại từ các cuộc tấn công trong thế giới thực.
Tổ chức cần lập các đội chức năng chéo, đảm bảo họ quan tâm tới AI, những người tuân thủ pháp luật, tuân thủ các nguyên tắc về dữ liệu và phân tích dữ liệu, bảo mật và quyền riêng tư, để:
1. Nắm bắt lỗ hổng của AI, đảm bảo có sự giải thích phù hợp khi rủi ro xảy ra.
2. Nhận thức của nhân viên về AI thông qua chương trình giáo dục rủi ro AI.
3. Dữ liệu AI nội bộ cần phải được bảo mật và được chia sẻ bằng chương trình bảo vệ dữ liệu.
4. Hỗ trợ độ tin cậy và bảo mật kết hợp quản lý rủi ro trong các mô hình AI hoạt động.
5. Áp dụng các biện pháp bảo mật AI cụ thể chống lại các cuộc tấn công mạng.
Hình 4: Framework quản lý rủi ro AI. (Nguồn: Gartner)
DN có nên cho phép các sản phẩm và các dịch vụ thông minh của họ phát triển một cách tự chủ hay là nên “khóa” các thuật toán và cập nhật chúng theo định kỳ? Nếu các công ty chọn “khóa” các thuật toán và cập nhật chúng theo định kỳ thì khi nào khóa và tần suất thực hiện cập nhật là bao nhiêu? DN nên đánh giá và giảm thiểu rủi ro đó. Rủi ro cũng có thể xảy ra ngay cả khi các mẫu thuật toán đã học ổn định và không có sự thay đổi khái niệm. Ví dụ, phát triển hệ thống thiết bị y tế trong bệnh viện dựa trên ML, thiết bị ở trong bệnh viện đã sử dụng dữ liệu của các bệnh viện lớn. Nhưng khi sử dụng thiết bị ở bên ngoài thị trường, dữ liệu y tế được cung cấp bởi các nhà cung cấp dịch vụ chăm sóc ở vùng nông thôn mà dữ liệu đó có thể không giống với dữ liệu đang phát triển. Với sự đa dạng và tốc độ thay đổi của thị trường, ngày càng trở nên khó lường trước những gì sẽ xảy ra trong môi trường mà AI hoạt động trong đó, và không có lượng dữ liệu nào có thể nắm bắt tất cả các sắc thái xảy ra trong thế giới thực.
Các chương trình máy tính cập nhật thông tin mới và sau đó thay đổi cách chúng đưa ra quyết định, làm thiên vị trong đầu tư, trong cho thuê hoặc cho vay, gây ra tai nạn ô tô.
Quản lý rủi ro AI rất khó nhưng không có nghĩa là trì hoãn. DN cần hợp tác và thiết lập mục tiêu các ngành nghề kinh doanh là điều kiện tiên quyết sau đó đưa ra các nhiệm vụ cụ thể như quản lý băng thông khi sử dụng AI. Tuy nhiên, nếu không tiến triển rủi ro AI thậm chí còn nguy hiểm hơn.
Nếu các nhà lãnh đạo quyết định sử dụng ML, câu hỏi tiếp theo là: Công ty có nên cho phép nó liên tục phát triển hay chỉ giới thiệu các phiên bản thử nghiệm và khóa nó trong một khoảng thời gian? Liệu lựa chọn thứ hai có giảm thiểu rủi ro? Khóa không thay đổi thực tế là các thuật toán ML thường dựa trên các quyết định mang tính xác suất. Hơn nữa, đầu vào nhiều dữ liệu hơn thường dẫn đến hiệu suất tốt hơn. Mức độ cải tiến có thể khác nhau. Cải tiến các thuật toán lớn hay nhỏ trong hệ thống phụ thuộc vào khối lượng dữ liệu khác nhau.
Các quyết định có thể thay đổi khi một thuật toán được mở khóa. Sự thay đổi môi trường cũng quan trọng vì hệ thống đưa ra quyết định đang phát triển phụ thuộc vào môi trường. Ví dụ: ô tô tự lái hoạt động trong môi trường xung quanh liên tục bị thay đổi vì hành vi của các trình điều khiển khác. Hệ thống định giá, chấm điểm tín dụng và giao dịch có thể phải đối mặt với một thị trường thay đổi khi DN bước sang một giai đoạn mới. Thách thức là đảm bảo rằng hệ thống ML và hệ số môi trường tham gia, giúp hệ thống đưa ra quyết định phù hợp. Khóa một thuật toán không loại bỏ sự phức tạp của hệ thống mà nó được nhúng vào. Lỗi do sử dụng dữ liệu từ các nhà cung cấp bên thứ ba để đào tạo thuật toán hoặc lỗi do sự khác biệt về kỹ năng người dùng có thể xảy ra. Trách nhiệm pháp lý vẫn có thể được phân bổ giữa các nhà cung cấp dữ liệu, người phát triển thuật toán, người triển khai và người dùng.
Có được mô hình rõ ràng AI là bước đầu tiên tổ chức cần thực hiện để quản lý rủi ro. Quản lý rủi ro AI đặt ra các yêu cầu mới. Các điều khiển thông thường không đủ đảm bảo an ninh và độ tin cậy.
Quyền riêng tư và bảo mật dữ liệu được xem là một rào cản chính đối với các dự án AI. Để quản lý rủi ro của AI, các nhà quản lý DN nên phát triển các quy trình thích hợp, ban lãnh đạo và hội đồng quản trị có các quyết định sáng suốt, đặt câu hỏi phù hợp và áp dụng các tiêu chuẩn chính xác, phù hợp là các bước quan trọng. Đối xử với ML như con người. Giám đốc điều hành cần nghĩ về ML như một thực thể sống, không phải là một công nghệ mạnh nhất, cũng như kiểm tra nhận thức của nhân viên để đảm bảo không tiết lộ cách AI làm khi được thêm vào ứng dụng kinh doanh.
Thử nghiệm các hệ thống ML trong phòng thí nghiệm khi không thể dự đoán được hiệu suất. Giám đốc điều hành nên yêu cầu phân tích đầy đủ về cách thức nhân viên, khách hàng, hoặc những người dùng áp dụng hệ thống này và các phản ứng với các quyết định từ AI. Ngay cả khi các cơ quan quản lý không yêu cầu thì DN khi muốn đưa các sản phẩm dựa trên ML vào các thử nghiệm cần có hướng dẫn và kiểm soát để đảm bảo an toàn, hiệu quả và công bằng trước khi triển khai.
DN cần phân tích các quyết định về sản phẩm AI trên thị trường thực tế, nơi có nhiều người dùng khác nhau, để xem xét chất lượng của các quyết định đó. Ngoài ra, cần so sánh chất lượng của các quyết định của các thuật toán trong các tình huống tương tự với khi không sử dụng chúng. Trước khi triển khai các sản phẩm trên quy mô lớn cần cẩn thận loại bỏ sản phẩm chưa qua thử nghiệm. DN nên xem xét thử nghiệm chúng ở thị trường hạn chế để hiểu rõ hơn về độ chính xác của chúng và hành vi khi có nhiều yếu tố khác nhau, như khi người dùng không có chuyên môn như nhau, dữ liệu từ các nguồn khác nhau, hoặc môi trường thay đổi. Thất bại trong cài đặt báo hiệu cần phải cải thiện hoặc gỡ bỏ các thuật toán ML.
DN nên phát triển các kế hoạch để có chứng nhận kiểm thử các sản phẩm AI trước khi đưa ra thị trường. Các công ty có thể cần phát triển một framework tương tự của riêng mình. Giám sát liên tục (sản phẩm và dịch vụ và môi trường) dựa trên ML, khi đó DN có thể thấy rằng công nghệ của họ không như thiết kế ban đầu. Thiết lập các cách để kiểm tra xem các công nghệ này hoạt động trong một giới hạn thích hợp, phù hợp với tiêu chuẩn và các quy định của pháp luật đã ban hành. Thường xuyên giám sát, đo lường và kiểm tra các chương trình có các công cụ bảo trì phòng ngừa rủi ro trong sản xuất hay trong lĩnh vực an ninh mạng. Ví dụ như các công ty có thể tiến hành các cuộc tấn công thử vào hệ thống AI xem sức mạnh phòng thủ của hệ thống CNTT trong DN thế nào.
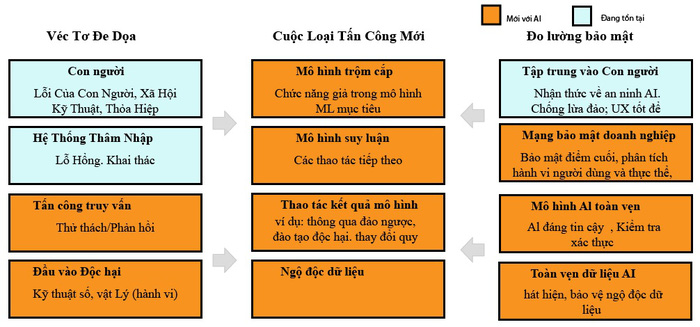
Hình 5: Các mối đe dọa và biện pháp bảo mật mới.
Hình 5 cho thấy các mối đe dọa và biện pháp bảo mật mới. Các mối đe dọa và các hình thức tấn công này có thể ít kịch tính nhưng nghiêm trọng đối với DN.
Kết luận
AI đang đi đầu trong mục tiêu thay đổi nhanh trong chiến lược chuyển đổi số của các DN. Thế nhưng thay đổi càng nhanh thì không phải là không có rủi ro. Cách AI có thể được sử dụng để tăng cường quyết định tiếp tục mở rộng. Các ứng dụng AI mới sẽ ngày được tạo ra nhiều hơn, đem lại thay đổi cơ bản nhưng đôi khi cũng gặp những thách thức và khó khăn không nhỏ trong quy trình công việc. Cuối cùng, DN nào triển khai AI cho phép con người và ML làm việc cùng nhau sẽ có lợi thế hơn so với DN chỉ có con người hoặc máy móc tự làm.
Tóm tắt: Với sự phát triển của cơ sở hạ tầng thông tin và những đổi mới nhằm cung cấp một tiêu chuẩn cao về dịch vụ tài chính, các ngân hàng, tổ chức tín dụng, cùng với các tổ chức tài chính khác sử dụng những công nghệ mới nhất hiện có theo nhiều cách khác nhau, phù hợp với nhu cầu của người đi vay và người cho vay, để tạo thuận lợi cho các giao dịch thanh toán. Đối với các công ty công nghệ tài chính (Fintech), một trong những nền tảng hấp dẫn nhất là cho vay ngang hàng (P2P) nhằm mục đích để các nhà đầu tư và người đi vay cùng bắt tay nhau, loại bỏ các trung gian truyền thống. Vai trò của tổ chức tài chính là trung gian, kiểm soát, đánh giá rủi ro và cung cấp các nền tảng cho vay P2P đổi mới. Trong thời đại của dữ liệu lớn (Big Data), nguồn thông tin đa dạng từ hành vi chi tiêu của khách hàng, hoạt động trên mạng xã hội và thông tin vị trí, cùng với các phương pháp truyền thống nhằm chấm điểm tín dụng được phù hợp và chính xác.
Từ khóa: Dữ liệu lớn, máy học, tài trợ cộng đồng, chấm điểm rủi ro tín dụng, cho vay ngang hàng.
1. Đặt vấn đề
Giám sát rủi ro thanh khoản và tín dụng là một trong những vấn đề chính trong hoạt động ngân hàng. Rủi ro thanh khoản do đầu tư thiếu tính thị trường, khi tài sản cơ bản không thể được mua hoặc bán đủ nhanh để phòng ngừa hoặc giảm thiểu tổn thất. Rủi ro tín dụng xảy ra do việc nắm giữ trái phiếu, hay bất kỳ sự chậm trễ nào trong việc thanh toán khoản đi vay khi đến hạn là một trong những mối quan tâm chính của các nhà đầu tư. Do đó, họ muốn phân tích tín dụng trước khi phê duyệt bất kỳ khoản vay nào, đồng thời đánh giá được khả năng rủi ro vỡ nợ của một người đi vay.
Điểm tín dụng cho người đi vay là con số dựa trên thông tin trong hồ sơ tín dụng của người nộp đơn, ngụ ý xác suất người đi vay hoàn trả. Về mặt lý thuyết, một người đi vay tiềm năng có số điểm càng cao thì rủi ro vỡ nợ của người đó càng ít. Điểm tín dụng được phát triển bởi một công ty phầm mềm phân tích lớn cung cấp sản phẩm và dịch vụ cho cả doanh nghiệp và người tiêu dùng có tên là Fair Isaac Corporation vào những năm 1950 được gọi là điểm FICO. Điểm FICO nằm trong khoảng từ 300 đến 850 hoặc 250 đến 900, tùy thuộc vào mô hình chấm điểm và dựa trên một số yếu tố, bao gồm lịch sử thanh toán, số dư tài khoản, loại tín dụng được sử dụng, độ dài của lịch sử tín dụng và các đơn đăng ký tín dụng mới. Tùy thuộc vào cách một cá nhân thay đổi, xử lý các hóa đơn và tài khoản tín dụng, điểm FICO sẽ thay đổi tương ứng.
Trong các mô hình trước đây, các yếu tố như thu nhập, độ tuổi, vị trí cư trú, nghề nghiệp hoặc lịch sử việc làm của người nộp đơn không ảnh hưởng quá nhiều, nhưng trong giai đoạn phát triển của dữ liệu lớn, tất cả những yếu tố này và các hoạt động truyền thông xã hội, mô hình mua sắm, nhiều thông tin khác được sử dụng để chấm điểm tín dụng. Mục tiêu cuối cùng của phân tích tín dụng là xem xét nguồn lực tài chính của người nộp đơn và khả năng của người đó có thể đáp ứng các tiêu chí đánh giá. Xếp hạng tín dụng tác động đến lãi suất mà người vay phải trả khi đăng ký khoản vay trên nền tảng P2P, người vay càng có nhiều rủi ro thì mức lãi suất phải chịu càng cao.
2. Cho vay P2P
Vào những năm 1960, khi thẻ tín dụng được sử dụng rộng rãi, nhân viên tại các ngân hàng bắt đầu sử dụng cách chấm điểm tín dụng bằng cách ứng dụng các phương pháp thống kê cho một loạt thông tin định lượng như lịch sử thanh toán, thu nhập… Khi đó, tính điểm tín dụng là việc sử dụng các mô hình phân tích, tổng hợp để chuyển đổi dữ liệu có liên quan thành điểm số bằng cách mô tả xác suất vỡ nợ của người đi vay tiềm năng. Với cách thiết lập quan hệ lâu dài với khách hàng vay, nhân viên đưa ra quyết định cho vay chủ yếu dựa trên thông tin chủ quan như sự trung thực, năng lực hoặc độ tin cậy, còn các yếu tố khách quan như báo cáo thu nhập hoặc bảng cân đối kế toán, có thể định lượng và kiểm chứng được. Với dữ liệu cứng trong tay, các công ty chấm điểm tín dụng có thể khắc phục được vấn đề bất cân xứng thông tin giữa nhà đầu tư và người đi vay.
Có rất nhiều Fintech cung cấp dịch vụ cho vay P2P như Lending Club, Zopa, Prosper và Peerform, Tala… Nói chung, nền tảng cho vay P2P hoạt động như sau: Một người vay tiềm năng đăng ký một khoản vay, nền tảng cho vay thực hiện chấm điểm tín dụng dựa trên dữ liệu do người đi vay cung cấp. Nếu người đi vay không đáp ứng các tiêu chí nhất định, đơn đăng ký sẽ bị từ chối, còn khi được chấp thuận, một mức lãi suất được ấn định cho người vay theo điểm tín dụng của họ. Nếu người đi vay không chấp nhận lãi suất phát sinh, hoặc khoản vay bị từ chối, người vay được yêu cầu cung cấp thêm thông tin để đánh giá mới. Nếu người đi vay chấp nhận lãi suất phát sinh, khoản vay sẽ được thêm vào nền tảng trực tuyến và được tài trợ bởi một số nhà đầu tư. Mối quan tâm chính trong quá trình này là đánh giá sự tin cậy của các nền tảng cho vay.
Đã có nhiều phương pháp, thuật toán để chấm điểm tín dụng và phân loại các khoản vay. Trong số đó, hồi quy logistic (Logistic Regression) và rừng ngẫu nhiên (Random Forest) – một phương pháp học máy (Machine Learning) tổng hợp để phân loại, hồi quy và các nhiệm vụ khác được sử dụng làm thuật toán phổ biến.
Xu hướng chấm điểm tín dụng mới sử dụng tất cả các yếu tố, gồm cả dữ liệu thay thế, nằm ngoài phạm vi của phương pháp tính điểm truyền thống. Ví dụ, chất lượng tín dụng của bạn bè người đi vay không chỉ cải thiện sự thành công trong việc huy động vốn và phê duyệt khoản vay, mà còn liên quan đến tỷ lệ vỡ nợ và lãi suất, mối quan hệ tích cực giữa khả năng vỡ nợ của một người bạn và xác suất vỡ nợ của một người đi vay luôn tồn tại, hay từ phương tiện truyền thông xã hội, các công cụ khai thác cũng được sử dụng để phân tích, đánh giá, mục đích vay cũng là một yếu tố quyết định khả năng vỡ nợ. Nền tảng huy động vốn cộng đồng (một thuật ngữ chung cũng bao gồm cho vay P2P) là một công cụ tự đánh giá cần thiết cho những cá nhân đang xem xét đơn đăng ký vay từ các nền tảng trực tuyến.
3. Hiệu quả của các kỹ thuật Machine Learning trong phân loại và chấm điểm tín dụng ngân hàng
Phương pháp phân loại Machine Learning hồi quy logistic, rừng ngẫu nhiên và cây quyết định (Decision Tree – một trong những phương pháp tiếp cận mô hình dự đoán được sử dụng trong thống kê, khai thác dữ liệu và Machine Learning để kết luận về giá trị mục tiêu của mặt hàng đó) trên hệ thống tệp phân tán Hadoop (HDFS).
Điểm tín dụng truyền thống thường dễ dàng hơn để giải thích một khách hàng sẽ được tính điểm tín dụng như thế nào và cách quản lý mỗi khách hàng là tương tự nhau.
Các mô hình Machine Learning chấm điểm tín dụng dựa trên trí tuệ nhân tạo (AI) kết hợp giữa lịch sử tín dụng của khách hàng và tiềm năng của Big Data. Sử dụng một nguồn lớn các thông tin được khai thác từ AI để cải thiện các quyết định tín dụng và mang lại sự thật ngầm hiểu tốt hơn so với một chuyên gia phân tích là con người.
Rủi ro tín dụng vẫn là một trong những thử thách tài chính lớn nhất trong hoạt động ngân hàng. Hiện tại, các tổ chức tài chính vẫn chưa hoàn toàn tối ưu hóa được khả năng dự đoán của rủi ro số hóa. Theo như báo cáo từ McKinsey & Company (một công ty tư vấn quản lý toàn cầu) cho thấy rằng, Machine Learning có thể giảm thâm hụt tín dụng lên tới 10%, với hơn một nửa các nhà quản lý tín dụng kỳ vọng rằng thời gian xử lý tín dụng sẽ giảm khoảng 25 tới 50%.
Các mô hình truyền thống thường tập trung vào tài chính của bên vay, phân loại khách hàng dựa trên các thông số, lịch sử chi trả và nhiều cân nhắc khác. Điều này khiến các viện tài chính dễ dàng hơn khi làm rõ mối quan hệ giữa hành vi người tiêu dùng và điểm tín dụng. Tuy nhiên, việc người tiêu dùng sử dụng tiền, tiết kiệm và cho vay đang thay đổi, và công nghệ cũng vậy. Với Machine Learning, các ngân hàng và tổ chức tài chính đã có thể áp dụng khoa học thay vì dự đoán. Các viện tài chính lớn đã sử dụng AI để phát hiện và ngăn ngừa các giao dịch giả trong nhiều năm nay.
Mô hình chấm điểm theo AI kết hợp lịch sử tín dụng của khách hàng và sức mạnh của Big Data, sử dụng một lượng lớn các nguồn lực để tăng khả năng xét duyệt tín dụng và thường đạt được kết quả chính xác hơn so với các nhà phân tích thông thường. Các ngân hàng có thể phân tích lượng dữ liệu lớn hơn – cả tài chính lẫn phi tài chính – bằng cách chạy kết hợp các thông tin nhằm dự đoán sự tương tác của các biến.
Xây dựng một hệ thống rủi ro tín dụng phân tầng: Mô hình Proof of Concept cho thấy chấm điểm tín dụng dựa trên AI của Tập đoàn Intel (Hoa Kỳ) có thể giúp các ngân hàng tăng khả năng của Machine Learning và phân tích dữ liệu. Sử dụng thư viện tối ưu của Intel trong bộ vi xử lý Intel® Xeon® Gold 6128 giúp các ứng dụng Machine Learning có thể dự đoán nhanh hơn khi chạy tập dữ liệu tín dụng của người Đức chứa hơn 1.000 hồ sơ vay tín dụng. Hệ thống này gồm các bước và các thành phần chính sau:
– Dataset analysis: Là sự bắt đầu của việc khai thác dữ liệu, bao gồm cả phân tích và xác định các biến.
– Pre-processing: Việc tiền xử lý nhằm chuyển hóa dữ liệu trước khi đưa vào thuật toán. Trong trường hợp này, nó sẽ bao gồm việc chuyển đổi các biến nhóm sang biến số bằng nhiều công nghệ khác nhau.
– Feature selection: Trong bước này, mục tiêu là để loại bỏ các tính năng không liên quan gây tăng thời gian xử lý. Điều này có thể thực hiện bằng Random Forest hoặc thuật toán Xgboost (thư viện phần mềm mã nguồn mở cung cấp một khuôn khổ tăng độ dốc đều đặn cho C++, Java, Python, R, Julia, Perl và Scala, hoạt động trên Linux, Windows và macOS).
– Data split: Dữ liệu sau đó được tích thành các chuỗi và thử nghiệm các tập cho các phân tích sâu hơn.
– Model building: Mô hình Machine Learning được chọn cho đào tạo (training).
– Prediction: Trong giai đoạn này, mô hình được đào tạo dự báo về kết quả của dữ liệu nạp vào dựa trên những gì đã học.
– Evaluation: Để tính toán độ hiệu quả, nhiều tiêu chuẩn đánh giá khác nhau có thể được dùng như độ chính xác, Precision-Recall.
Nhiều tổ chức tài chính sử dụng các mô hình chấm điểm tín dụng để giảm rủi ro trong đánh giá tín dụng cũng như trong việc cấp và giám sát tín dụng. Các mô hình chấm điểm tín dụng dựa trên các lý thuyết thống kê cổ điển được sử dụng rộng rãi. Tuy nhiên, các mô hình này không dùng được khi có số lượng lớn dữ liệu đầu vào. Điều này ảnh hưởng đến tính chính xác của dự báo dựa trên mô hình. Theo nhiều nghiên cứu thực nghiệm, các kỹ thuật Machine Learning cùng với các thuật toán khai thác dữ liệu (Data Mining) khác dựa trên cách tính toán và chuyển đổi kiểu mới hoạt động tốt hơn cho mục đích dự báo. Các thuật toán Machine Learning được thiết kế để học từ một lượng lớn dữ liệu lịch sử và sau đó tính toán ra kết quả dự báo. Quá trình kinh doanh điển hình cho việc cung cấp dịch vụ cho vay là: Nhận các hồ sơ vay vốn, đánh giá rủi ro tín dụng, ra quyết định về việc cho vay và giám sát việc hoàn trả vốn gốc và lãi. Trong quá trình đó, các vấn đề có thể xảy ra, chẳng hạn như làm thế nào để đẩy nhanh tiến trình thẩm định tín dụng và làm thế nào để giám sát quá trình hoàn trả và thực hiện can thiệp kịp thời khi khả năng vỡ nợ xuất hiện. Để giải quyết hai vấn đề này, có thể xây dựng hai mô hình trong hai tiến trình khởi tạo vốn vay và tiến trình giám sát:
– Trong quá trình khởi tạo: Đối tượng cần kiểm tra bao gồm tất cả các ứng viên nộp đơn xin vay vốn. Mô hình có thể được sử dụng để phân tích thông qua dữ liệu lịch sử của các hồ sơ đăng ký vay vốn, qua đó, đánh giá liệu một ứng viên mới có đủ tin cậy để được vay hay không nếu các chỉ tiêu đặc trưng của người nộp đơn được cung cấp, như thu nhập, tình trạng hôn nhân, tuổi, lịch sử tín dụng (chẳng hạn đã từng nợ xấu hay chưa…).
– Trong quá trình giám sát: Hệ thống kiểm tra dữ liệu của người được duyệt vay vốn. Bằng cách sử dụng dữ liệu lịch sử hồ sơ hoàn trả và trạng thái đặc điểm của khách hàng đã hoàn thành toàn bộ quá trình vay vốn, chúng ta có thể đào tạo mô hình khác để đưa ra dự kiến về việc liệu khách hàng này có xác suất lớn hay không khả năng vỡ nợ; bằng cách quan sát hồ sơ hoàn trả của người nộp đơn cho một vài giai đoạn hoàn vốn đầu tiên và thay đổi các đặc tính, mô hình này sẽ giúp tạo ra các điều chỉnh mới dựa trên thông tin cập nhật. Quy trình tự động này hiệu quả hơn về thời gian xử lý cũng như tính chính xác so với cách làm truyền thống.
Có rất nhiều thuật toán Machine Learning, tính hiệu quả của các thuật toán phụ thuộc vào dữ liệu và cấu trúc dữ liệu cụ thể. Cách chung để tìm một mô hình thích hợp cho một bộ dữ liệu cụ thể hoặc một loại tập dữ liệu là áp dụng thuật toán đã được sử dụng rộng rãi và đã được kiểm chứng. Hai tiến trình trên có các mô hình khác nhau. Tiến trình giám sát hoàn trả tương tự như tiến trình cấp vốn vay, nhưng nó được học và đúc rút ra từ các dữ liệu lịch sử khác nhau, cụ thể là từ khách hàng cũ đã hoàn thành việc trả nợ, bao gồm toàn bộ lịch sử hồ sơ thanh toán và các đặc điểm của khách hàng. Một thuật toán Machine Learning khác có thể được ứng dụng để phù hợp tương ứng với các thay đổi của cấu trúc dữ liệu. Ngày nay, các thuật toán Machine Learning hay được sử dụng nhất có thể được phân loại đơn hoặc phân loại toàn bộ. Các đại diện của các thuật toán phân loại đơn là CART, Naive Bayes, SVM, Logistics. Việc sửa đổi các bộ phân loại đơn, nhiều mô hình cùng học để giải quyết cùng một vấn đề, được sử dụng rộng rãi, chẳng hạn như Random Forests, CART-Adaboost… Về cơ bản, Machine Learning cũng giống như việc dạy kiến thức tài chính cho người học mới dựa trên số liệu lịch sử để thực hiện xác định chất lượng của khoản vay, sau đó họ sẽ có kinh nghiệm để tự quyết định. Trong lĩnh vực ngân hàng, bảo hiểm, dựa trên Machine Learning có thể phát triển các ứng dụng, bao gồm chấm điểm tín dụng (Credit Score), phân tích rủi ro (Risk Analytics), phát hiện gian lận (Fraud Detection), bán chéo (Cross-Sell).
Ứng dụng AI vào quy trình chấm điểm tín dụng tuy đã phổ biến trên thế giới nhưng là một lĩnh vực mới tại Việt Nam. Khảo sát từ McKinsey & Company tại khu vực châu Âu, châu Á và Bắc Mỹ cho thấy, hàng loạt ngân hàng đã ứng dụng AI để đưa ra quyết định cho vay chỉ trong 5 phút, giải ngân chưa đến 24 giờ. Trong khi đó, quy trình cho vay, đơn cử với doanh nghiệp vừa và nhỏ phải được xét duyệt trong 3 – 5 tuần, chờ giải ngân gần ba tháng.
Công nghệ này có thể tạo bước ngoặt lớn cho ngành tài chính – ngân hàng là do lượng lớn dữ liệu phi truyền thống được đưa vào để phân tích, đánh giá. Thông thường, để xác định mức độ an toàn tín dụng của bên đi vay hoặc người mở thẻ, ngân hàng thường dựa vào dữ liệu thể hiện trực tiếp khả năng tài chính của khách hàng, bao gồm hợp đồng lao động, sao kê lương, lịch sử tín dụng được ghi nhận trên các trung tâm thông tin tín dụng của nhà nước hoặc tư nhân (gọi chung là CIC). Tuy nhiên, các phương pháp này còn nhiều hạn chế. Những người chưa từng đi vay, chưa từng mở thẻ sẽ không có lịch sử tín dụng. Đồng thời, trong nhiều lĩnh vực, người mở thẻ không có hợp đồng lao động, sao kê lương phản ánh đúng thu nhập thực tế… Kể cả đối với những người đã đi vay, sau nhiều năm hoàn cảnh tài chính cá nhân của khách hàng cũng đã thay đổi, thông tin ghi nhận trên CIC không còn cập nhật. Trong khi đó, với phương pháp chấm điểm tín dụng sử dụng Big Data và AI, tất cả dữ liệu đều có giá trị. Chẳng hạn, dữ liệu hành vi, thói quen mua sắm trực tuyến, viễn thông, thanh toán các loại cước phí, thậm chí dữ liệu sức khỏe… Dù một khách hàng không có bất kỳ khoản vay ngân hàng nào nhưng họ vẫn có nhiều khoản khác cần thanh toán hằng tháng. Việc trả tiền đúng hẹn có thể phần nào xác định mức độ an toàn tín dụng của khách hàng. Ví dụ, thanh toán hóa đơn di động trả sau đúng định kỳ, nhân viên văn phòng thanh toán theo đúng yêu cầu các hóa đơn tiền điện, nước, Internet hay tiện ích khác. Khả năng chi tiêu trực tuyến… cũng tạo nên những thước đo mới. Những dữ liệu như vậy có thể cung cấp thông tin quan trọng về cách mọi người xử lý nghĩa vụ tài chính của mình, cách họ tôn trọng kỷ luật trong việc thanh toán đúng hạn. Đây chính là con đường tạo ra nguồn dữ liệu thay thế cho các ngân hàng trong việc đánh giá uy tín người dùng.
Giới chuyên gia tài chính đánh giá dữ liệu thay thế có khả năng hỗ trợ tốt trong đánh giá rủi ro tín dụng vì nó có độ phủ rộng. Việc kết nối thông tin từ các giao dịch kỹ thuật số mà khách hàng tham gia hằng ngày và xử lý dữ liệu bằng công nghệ mới tạo ra cơ chế giám sát hữu hiệu bổ sung cho các phương pháp đánh giá rủi ro tín dụng truyền thống. Với khối lượng dữ liệu cực lớn đặt ra thách thức không nhỏ trong việc phân tích để đưa ra kết quả nhanh chóng, chính xác và hữu ích. Khi đó, chỉ có công nghệ Machine Learning và AI mới đủ khả năng xử lý nguồn thông tin khổng lồ này. Nó có khả năng khám phá xu hướng hành vi và mô hình mua hàng của khách hàng. Tất cả các giao dịch khác nhau của họ như mua hàng tạp hóa, thanh toán hóa đơn tiện ích, chuyển tiền cho gia đình và bạn bè, mua vé xem phim… đều có thể được kết hợp để cung cấp cái nhìn toàn diện về hành vi tài chính và khả năng trả nợ.
Dữ liệu thay thế có khả năng giải quyết một số thách thức mà ngành Ngân hàng phải đối mặt. Các thuật toán, khoa học dữ liệu và AI sẽ thúc đẩy sự phát triển của dữ liệu thay thế, khuyến khích tổ chức, cá nhân tham gia và cải thiện điểm tín dụng của họ, kiểm tra các hoạt động gian lận và thúc đẩy cho vay thông minh.
Theo truyền thống, các ngân hàng sẽ đánh giá rủi ro tín dụng với những người chưa bao giờ đi vay bằng cách yêu cầu nộp thêm nhiều giấy tờ liên quan đến thu nhập có chứng nhận của bên thứ ba như hợp đồng lao động, sao kê bảng lương… càng thiếu thông tin thì người đi vay sẽ càng phải nộp nhiều thứ giấy tờ để chứng minh khả năng trả nợ của mình. Điều này khiến cho mô hình truyền thống trở nên dễ dàng hơn cho các định chế tài chính thể hiện mối quan hệ rõ ràng giữa khách hàng và chấm điểm tín dụng. Tuy nhiên, quy trình thủ công đòi hỏi nhiều thời gian, công sức xác minh, lưu trữ tài liệu… Trong xu hướng phát triển mảng bán lẻ của thị trường ngân hàng nhiều năm trở lại đây, phục vụ khách hàng sẽ phải xác minh một lượng thông tin người dùng rất lớn. Theo đó, quy trình mở thẻ tín dụng có thể kéo dài đến một tuần để gặp gỡ, tư vấn, thu thập giấy tờ, chứng minh tài chính, cung cấp hồ sơ và phát hành. Thẻ đến tay người dùng mất một tuần đến 10 ngày. Với thành công của dự án ứng dụng Big Data và AI vào quy trình duyệt hạn mức thẻ tín dụng, chỉ với thiết bị di động khách hàng điền thông tin cơ bản, sau đó nhận phê duyệt hạn mức thẻ nhanh nhất, đơn giản nhất có thể.
Big Data và AI đóng vai trò tiên phong trong việc phổ cập tài chính số. Bên cạnh giúp tìm hiểu khách hàng, Big Data còn giảm chi phí khoản vay, từ đó có thể mở rộng phạm vi kinh doanh. Ngoài ra, nó cũng tuân thủ quy định của Liên minh châu Âu về bảo vệ dữ liệu và quyền riêng tư cho tất cả các cá nhân, đảm bảo yếu tố bảo mật nhân thân và quyền riêng tư của người tiêu dùng. Khi công nghệ này được ứng dụng rộng rãi sẽ là một bước tiến mang tính cách mạng của hệ thống ngân hàng, giúp ngân hàng tối ưu hóa quy trình hoạt động, kiểm soát rủi ro hiệu quả hơn, gia tăng trải nghiệm khách hàng và thúc đẩy tài chính toàn diện, giúp ngày càng nhiều người tiếp cận sản phẩm, dịch vụ của ngân hàng.
Thời đại kinh tế số 4.0, cho vay kết hợp AI, Machine Learning và Blockchain. Mặc dù cho vay kỹ thuật số thay thế vẫn còn ở giai đoạn sơ khai, nhưng nó đã tạo được dấu ấn lớn trong ngành cho vay tiêu dùng. Một cuộc khảo sát được thực hiện bởi Hiệp hội Ngân hàng Hoa Kỳ công bố rằng, khối lượng cho vay có nguồn gốc từ các nền tảng cho vay kỹ thuật số tăng lên 90 tỷ USD vào năm 2020 tại Mỹ, chiếm khoảng 10% tổng thị trường cho vay. Lý do cho sự phổ biến ngày càng tăng của cho vay nền tảng số này là việc xử lý các ứng dụng cho vay không rắc rối và nhanh chóng hơn so với quy trình khá rườm rà, thiếu minh bạch và dự đoán trong lĩnh vực cho vay truyền thống. Lĩnh vực cho vay Fintech sử dụng nhiều công nghệ kỹ thuật số như AI, Machine Learning và công nghệ Blockchain để đi đầu trong cuộc đua vũ khí công nghệ. Những công nghệ này đang được chứng minh là then chốt trong việc xác định ngành công nghiệp cho vay sẽ được định hình lại như thế nào trong thập kỷ tới. Tài liệu cho vay từng là một quy trình cồng kềnh, nhưng hiện tại, các nhà tài chính sử dụng AI làm cho quá trình không chỉ nhanh hơn mà còn không bị lỗi và an toàn. AI hoạt động song song với các thuật toán Machine Learning để đánh dấu sự xứng đáng tín dụng của một cá nhân. AI có thể xử lý các ứng dụng trong vòng vài giây, làm cho quá trình phê duyệt thực sự có thể mở rộng. Điều này cũng làm giảm cơ hội cho vay mặc định và rủi ro cao hơn vì nó đánh giá dữ liệu thị trường để phân loại các khoản vay có cơ hội vỡ nợ cao hơn. Do đó, AI làm cho quá trình cho vay nhanh chóng và hiệu quả, cắt giảm cả chi phí cũng như nhân lực.
AI cũng giúp các công ty tinh chỉnh hệ thống của họ và do đó, ngăn chặn chúng khỏi tin tặc và các cuộc tấn công mạng. Hơn nữa, các thuật toán AI có khả năng tự động xác định dữ liệu cần thiết và tách biệt nó khỏi phần lớn thông tin. AI là một yếu tố quyết định quan trọng không chỉ trong cho vay số mà còn trong ngân hàng thương mại và tiêu dùng truyền thống.
Machine Learning thường được kết hợp với AI nhưng đã phát triển để đảm bảo sự chú ý của cá nhân ở các cấp độ cấp cao (các cấp điều hành như CEO, CFO, COO…). Nó không chỉ trao quyền tự động hóa xử lý khoản vay mà còn là bí mật về cách thuật toán tín dụng trở nên tốt hơn khi sử dụng dữ liệu. Các thuật toán Machine Learning thu thập dữ liệu ở quy mô lớn, hợp nhất dữ liệu này và xác định các mẫu trong dữ liệu này từ lịch sử cho vay. Dựa trên các mô hình này, nó đánh giá liệu người vay có đủ độ tin cậy hay không và điều chỉnh quá trình ra quyết định cho vay. Vì vậy, AI có thể đưa ra quyết định tín dụng ở quy mô lớn và chính Machine Learning giúp cải thiện thuật toán của mình, đồng thời đảm bảo đi trước trong việc hiểu các mẫu tín dụng và thị trường. Ứng dụng của nó bao gồm từ các mô hình tín dụng, xác định các gian lận để nhằm mục tiêu tiếp thị và thiết lập tỷ lệ.
Xây dựng trên sổ cái phân tán, Blockchain làm cho quá trình cho vay phi tập trung và không tin cậy. Mục đích của việc giới thiệu cho vay P2P trên Blockchain rất đa dạng. Nó có thể giúp thiết lập mối quan hệ trực tiếp giữa người cho vay và người đi vay bằng cách loại bỏ người trung gian khỏi quy trình. Trên nền tảng Blockchain, người cho vay có thể dễ dàng chuyển tiền cho người vay bằng cách chuyển quyền sở hữu tài sản của mình bằng các hợp đồng thông minh. Toàn bộ giao dịch cho vay có thể được chạy trên Blockchain và được thực hiện mặc dù không cần bất kỳ cơ quan trung gian nào. Nó có thể token hóa (chuyển đổi các loại tài sản thành dạng kỹ thuật số), chứng khoán hóa các khoản vay thành tài sản vi mô giao dịch được bằng cách chia chúng thành các đơn vị như cổ phiếu. Blockchain có thể mở rộng quy mô này để thu hút đầu tư bởi ngay cả các nhà đầu tư nhỏ lẻ. Một thị trường hoạt động cho khoản vay thị trường sẽ tạo ra thanh khoản và khả năng khám phá giá tốt hơn.
Theo nghiên cứu của công ty kiểm toán KPMG, tự động hóa quá trình Robot có thể cắt giảm 75% chi phí trong các dịch vụ tài chính. Hầu như mọi người cho vay Fintech đều tận dụng AI và Machine Learning để cho vay. Những tập đoàn lớn như Upstart, Amazon Lending và Avant đang đầu tư hàng triệu USD để tích hợp AI và Machine Learning cho quy trình đăng ký vay của họ. Việc tích hợp bắt đầu ngay từ lần đầu tiên trên trang web của người vay để giải ngân và hoàn trả khoản vay cuối cùng. Dữ liệu đang được sử dụng để phân tích và tạo ra các mô hình cho người cho vay một lợi thế trong việc cho vay và định giá các khoản vay.
Hiện tại, hoạt động cho vay ứng dụng Blockchain còn hạn chế, nhưng các dự án thí điểm đang diễn ra trong JP Morgan và Goldman Sachs cùng với một loạt các công ty cho vay khởi nghiệp để thúc đẩy giá trị và quy mô từ sự phân cấp và hợp đồng thông minh do ứng dụng công nghệ đem lại. Dự án Spring Network, Gem và CULedger có trụ sở tại Hoa Kỳ đều nhằm mục tiêu Blockchain như một giải pháp để trao đổi dữ liệu người vay cá nhân quan trọng nhưng ẩn danh. Điều này sẽ loại trừ khả năng xảy ra vụ tấn công tài khoản ngân hàng như vụ tấn công dữ liệu ngân hàng Equachus năm 2017, nơi hàng triệu người vay đã bị đánh cắp dữ liệu cá nhân của họ.
4. Kết luận
AI, Machine Learning và Blockchain là những công nghệ mang tính cách mạng, đang phá vỡ các ngành công nghiệp truyền thống trong tất cả các lĩnh vực, trong đó có ngành tài chính – ngân hàng. AI và Machine Learning hiện là những công nghệ chủ đạo để cho vay kỹ thuật số và nó còn một chặng đường dài phát triển và hoàn thiện. Ứng dụng Big Data và AI được sử dụng nhiều trong hoạt động tín dụng của các ngân hàng, hiện đang được thể hiện ở các nội dung sau: Phân tích hành vi khách hàng; phân khúc khách hàng và thẩm định hồ sơ; phát hiện và ngăn chặn hành vi lừa đảo, vi phạm pháp luật; nâng cao chất lượng dịch vụ, hiệu quả làm việc của nhân viên.
Để có thể khai thác được những lợi ích mà Big Data và AI mang lại như phân tích ở trên thì các ngân hàng cần nhận thức được tầm quan trọng của dữ liệu trong quá trình thẩm định tín dụng; xây dựng quy trình phù hợp với dữ liệu đầu vào phục vụ cho việc sử dụng dữ liệu; đảm bảo được nguồn nhân lực am hiểu về lĩnh vực Big Data và AI.
ThS. Đỗ Năng Thắng
Đại học Công nghệ thông tin và Truyền thông – Đại học Thái Nguyên
Trong vài năm qua, đã có rất nhiều lời thổi phồng xung quanh việc máy học sẽ biến đổi nhiều ngành công nghiệp như thế nào. Một ngành được nhắc đến thường xuyên là chăm sóc sức khỏe. Trong bài đăng trên blog sau đây, chúng ta sẽ khám phá một loại tác động có thể được thực hiện. Chúng tôi sẽ làm điều này bằng cách kiểm tra một bài báo đã được xuất bản trên tạp chí Nature vào năm 2021. Tên bài báo là Morphological and molecular breast cancer profiling through explainable machine learning.
Bài đăng này sẽ có ba phần: Mục đích của nghiên cứu, Phương pháp / Kết quả của nghiên cứu và Tại sao điều này lại quan trọng đối với Ung thư học và chăm sóc sức khỏe.
&&&&&
Mục đích
Trong lịch sử, đã có sự thiếu tích hợp giữa các kỹ thuật lập hồ sơ khác nhau trong nghiên cứu ung thư học. Điều đó để lại một số kết nối liên quan đến dữ liệu phân tử và dữ liệu hình thái học cho các đặc tính của bệnh ung thư. Các nhà nghiên cứu trong nghiên cứu này đã đặt mục tiêu tạo ra một liên kết thông qua học máy để thu hẹp khoảng cách giữa hai loại kỹ thuật tạo hồ sơ này. Nếu thành công, cách tiếp cận này có thể giúp tạo ra giả thuyết cho các kết nối giữa các loại tế bào và đặc tính phân tử.
Phương pháp / Kết quả
Thuật toán học máy
Phương pháp học máy mà nghiên cứu đã sử dụng dựa trên một kỹ thuật được gọi là lan truyền mức độ liên quan theo lớp (layer-wise relevance propagation – LRP). Truyền bá mức độ liên quan khôn ngoan theo lớp là một loại thuật toán học máy có thể giải thích được. Thay vì chỉ đưa ra đầu ra cho một đầu vào cụ thể, cách tiếp cận có thể làm nổi bật các tính năng đầu vào quan trọng nhất được sử dụng cho đầu ra đã cho. Đối với các tình huống sử dụng hình ảnh, các tính năng được đánh dấu là pixel. Kết quả là một bản đồ nhiệt trên hình ảnh đầu vào cho thấy pixel nào có tác động cao nhất đến việc lắc đầu ra. Các điểm ảnh có cường độ màu cao tương quan với điểm số liên quan cao cho các điểm ảnh được phân loại.
LRP tính toán các thuộc tính giải thích tổng đóng góp của một đối tượng đầu vào hơn là độ nhạy đối với biến thể đầu vào mà bạn sẽ nhận được trong các bản đồ nhiệt chú ý. Để có giải thích kỹ thuật hơn về cách hoạt động của việc truyền mức độ liên quan theo lớp, vui lòng tham khảo bài báo sau: Layer-Wise Relevance Propagation An Overview. .
Ứng dụng của thuật toán
Bây giờ chúng ta đã thảo luận về tổng quan về cách thức hoạt động của sự lan truyền mức độ liên quan theo lớp, chúng ta sẽ khám phá cách nhóm nghiên cứu có thể sử dụng điều này với dữ liệu hình thái ung thư và phân tử ung thư vú.
Đầu tiên, nhóm nghiên cứu đã tạo ra một cơ sở dữ liệu hình ảnh (Berlin Cancer Image Base, B-CIB, B-CIB) với các bản vá dữ liệu hình ảnh hiển vi có chú thích. Sử dụng LRP, nhóm nghiên cứu có thể phân biệt tế bào ung thư với tế bào lympho thâm nhiễm khối u (TiL). TiL là các tế bào lympho có thể xâm nhập vào mô khối u và nhận biết và tiêu diệt các tế bào ung thư. Mật độ hiện diện của chúng có thể được sử dụng như một đặc điểm để dự đoán khả năng sống sót của bệnh nhân. LRP cho phép thể hiện trực quan mật độ của chúng.
Sau đó, các nhà nghiên cứu dự đoán các đặc điểm phân tử bằng cách sử dụng dữ liệu hình ảnh hình thái học làm đầu vào cho thuật toán. Về cơ bản, cố gắng thu thập thông tin chi tiết về các đặc tính phân tử của bệnh nhân bằng cách quét hình ảnh. Dữ liệu được sử dụng để đào tạo bao gồm việc kết hợp dữ liệu hình ảnh và dữ liệu phân tử. Với mục đích của phần này của nghiên cứu và thông tin có sẵn thông qua tập dữ liệu để đào tạo, chú thích không gian thủ công là không cần thiết. Họ có thể yêu cầu thuật toán xác định các mẫu trong hình ảnh bằng cách cung cấp cho nó dữ liệu phân tử và dữ liệu hình thái trong quá trình huấn luyện. Để giảm kích thước của nhiệm vụ phân loại, họ đã sử dụng cách tiếp cận phân loại cao so với thấp cho các đặc điểm phân tử khác nhau. Thuật toán đưa ra phân loại dựa trên dự đoán về việc liệu biểu hiện của một đặc điểm phân tử là cao hay thấp, đưa ra một hình ảnh hình thái học làm đầu vào. Hai gen đạt điểm cao về mức độ biểu hiện là CDH1 và TP53.
Nhóm nghiên cứu cũng đã thử nghiệm với việc dự đoán bản địa hóa không gian của các đặc điểm phân tử. Dự đoán này cho thấy các vùng không gian có liên quan về mặt thống kê với các biểu thức đặc điểm phân tử nhất định. Thông tin này có thể được sử dụng để tạo ra các giả thuyết về mức độ liên quan của các thành phần cụ thể của vi môi trường khối u đối với sự hiện diện của các đặc điểm cấu hình khối u phân tử — thúc đẩy việc khám phá các liên kết tiềm năng có thể tồn tại giữa các đặc điểm mô học của khối u được hiển thị trong hình ảnh và phân tử các tính năng có thể được thể hiện. Các liên kết này có thể dẫn đến danh sách ứng viên được tạo sẵn cho các tính năng phân tử. Những danh sách này sẽ bao gồm các đặc điểm phân tử liên quan đến ung thư vú.
Cuối cùng, phương pháp học máy đã tiết lộ các đặc điểm không gian và hình thái có liên quan về mặt thống kê với các biểu hiện của các đặc điểm phân tử khác nhau. Thông tin này được hiển thị thông qua bản đồ nhiệt hiển thị cách trong hầu hết các trường hợp, các đặc điểm phân tử có mối liên hệ cụ thể với các nhóm hình thái được thử nghiệm (tế bào ung thư, TiL và mô đệm (tế bào hỗ trợ)).
Để kiểm tra tính hợp lệ của các kết quả, nhóm đã sử dụng một kỹ thuật gọi là nhuộm hóa mô miễn dịch (immunohistochemical – IHC) để so sánh kết quả với các bản đồ nhiệt được tạo ra từ thuật toán học máy. Họ đã sử dụng một bài kiểm tra quadrat để chỉ ra mối liên hệ giữa hai loại. Phép thử quadrat có thể được sử dụng để đo độ ngẫu nhiên trong không gian cho một mẫu điểm. Phép thử góc phần tư đo tính ngẫu nhiên trong không gian bằng cách sử dụng phép thử chi bình phương. Nhìn chung, các mẫu IHC phản ánh các mẫu được dự đoán từ thuật toán học máy xác thực phương pháp học máy.
Tại sao
Nghiên cứu mà chúng ta xem xét ngày hôm nay là một ví dụ tuyệt vời về cách học máy có thể được sử dụng cho mục đích nghiên cứu ung thư. Nó không nhất thiết sẽ thay thế các công cụ đã có sẵn, nhưng nó có thể hoạt động bổ sung cho chúng. Một số trường hợp sử dụng cho nghiên cứu ung thư liên quan đến việc tạo giả thuyết thông qua các mẫu mới có thể xuất hiện từ cách tiếp cận dựa trên học máy. Ví dụ về các giả thuyết có thể được tạo ra từ nghiên cứu được khám phá trong bài viết này chủ yếu liên quan đến các mối quan hệ mới được phát hiện giữa các đặc điểm phân tử phi không gian và thông tin không gian. Những mối quan hệ này có thể giúp phân loại khối u tinh tế hơn và danh sách ứng cử viên mới cho các liệu pháp nhắm mục tiêu tiềm năng.
Trong một ngành công nghiệp mà nhận dạng mẫu là rất quan trọng, học máy có thể hoạt động như một ánh sáng hướng dẫn để thúc đẩy khám phá xa hơn.